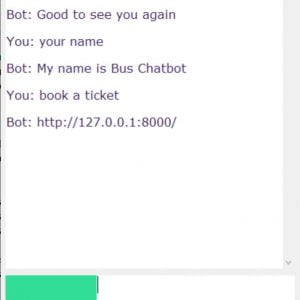
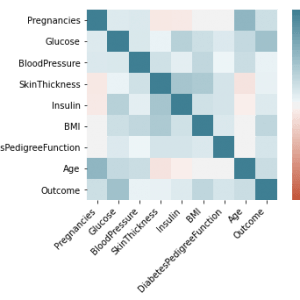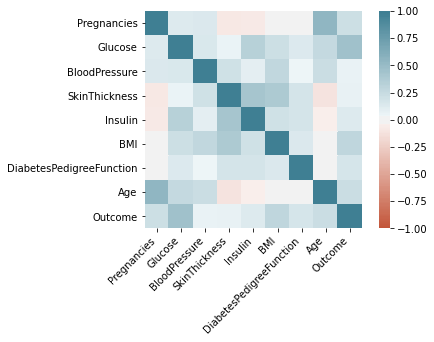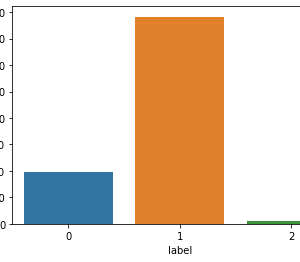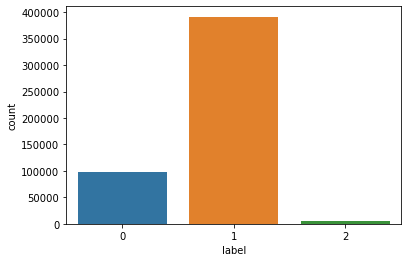Cyber Threat Analysis on Android Apps using Machine Learning
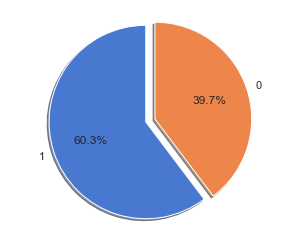
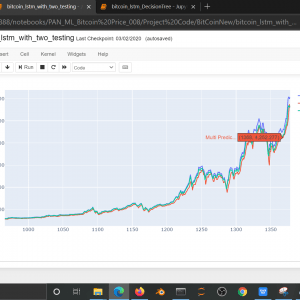
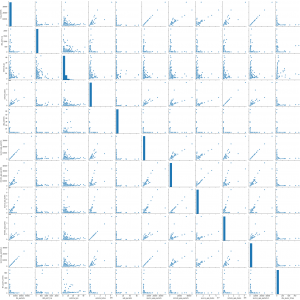
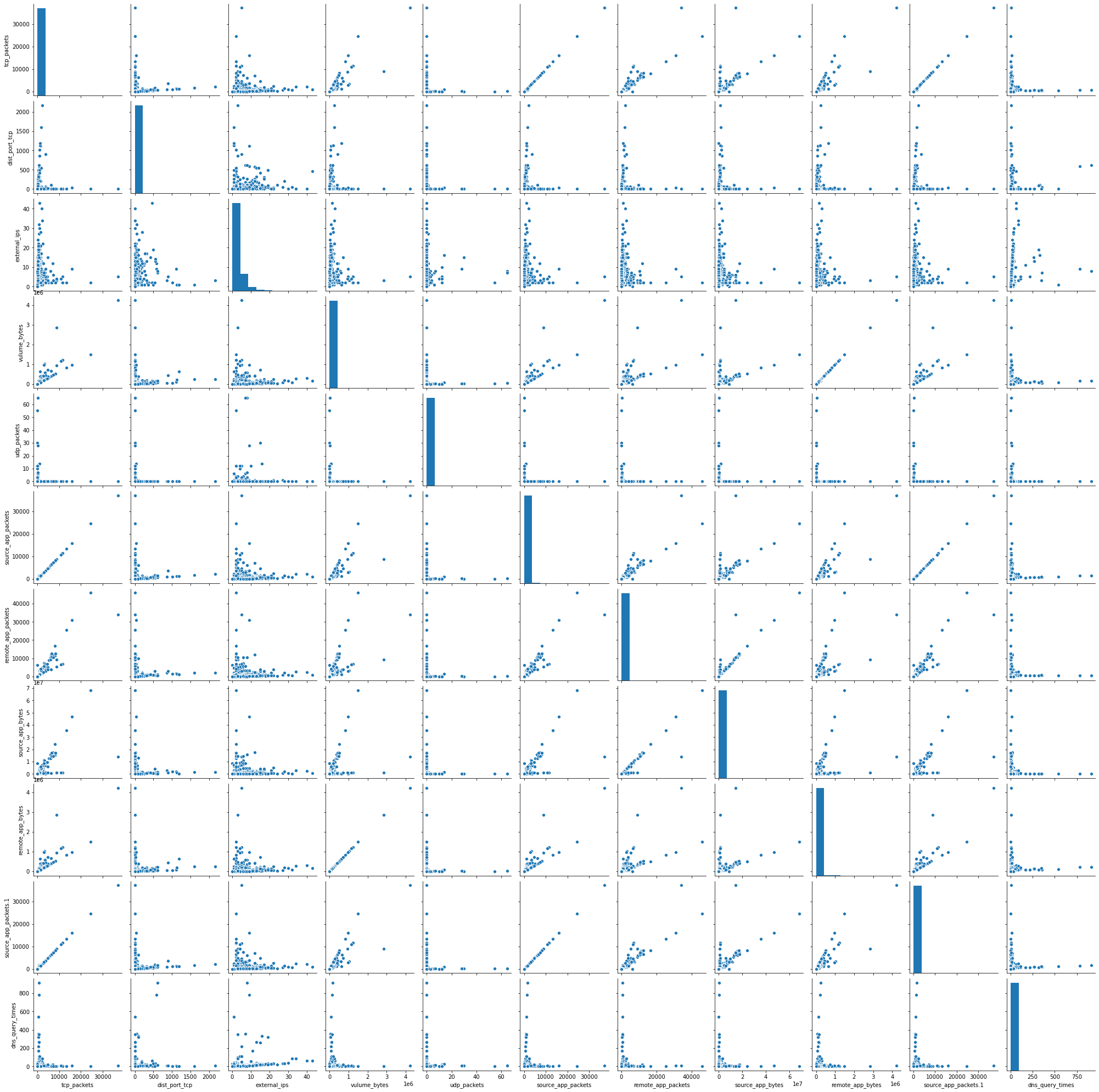
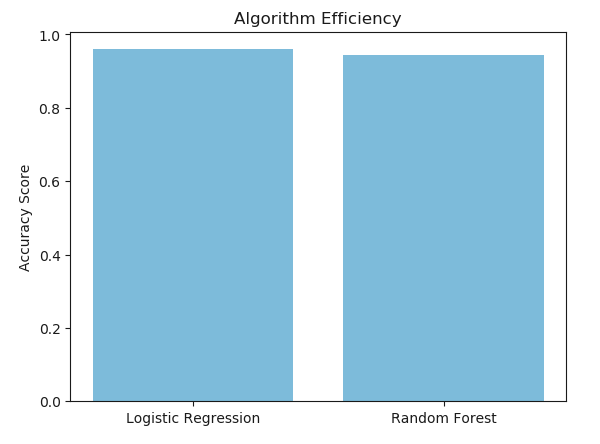
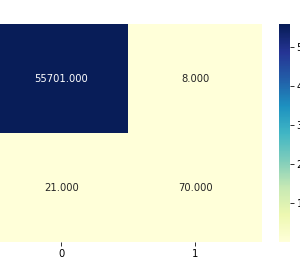
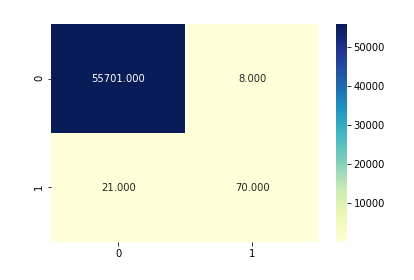
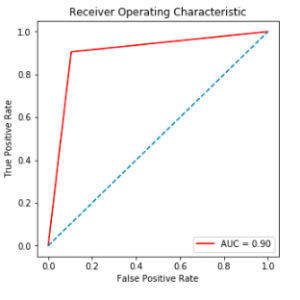
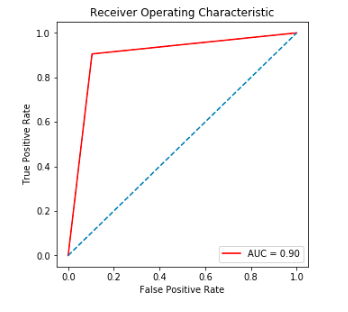
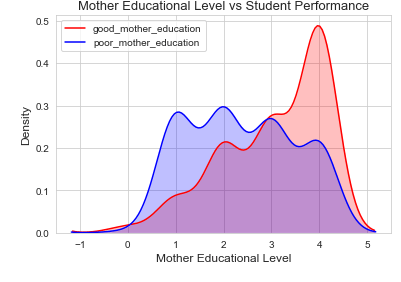
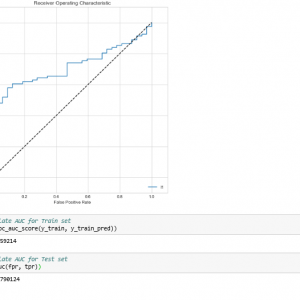
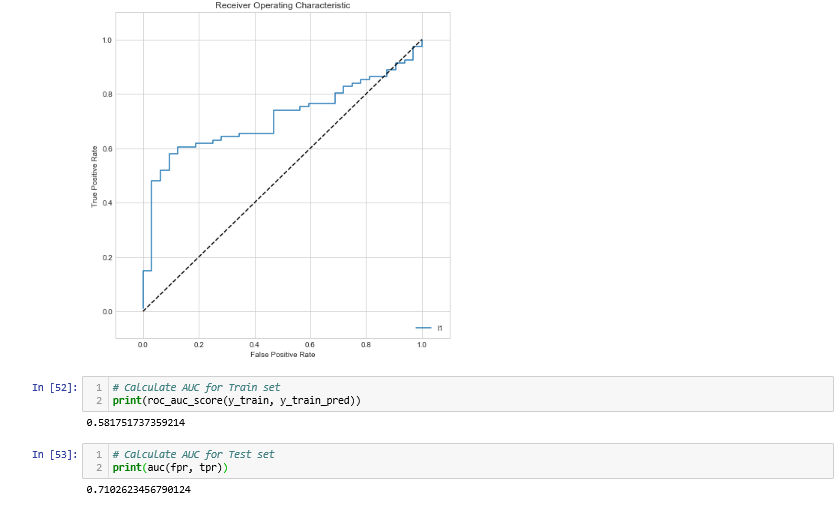
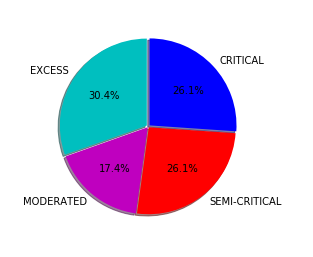
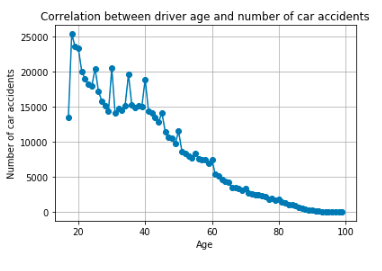
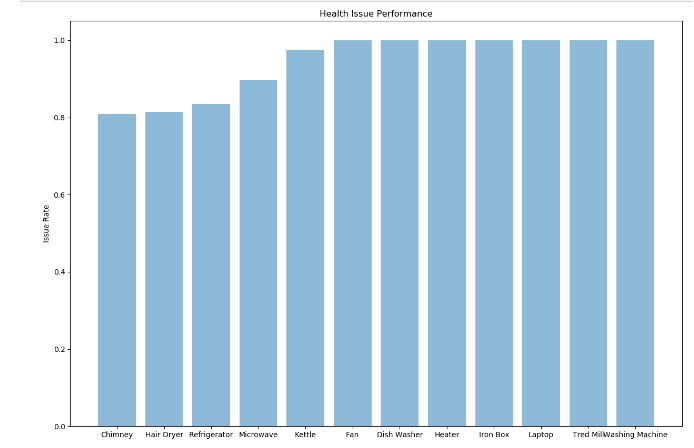
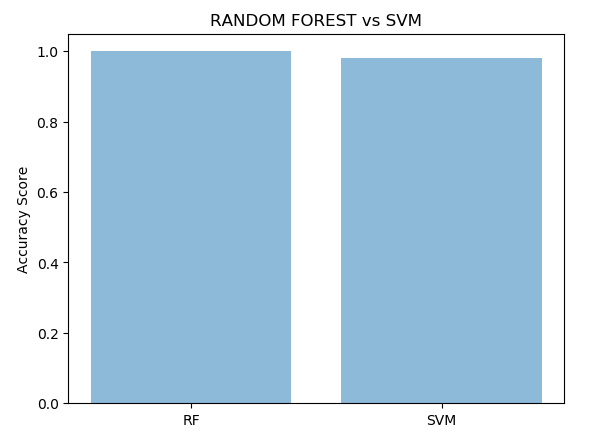
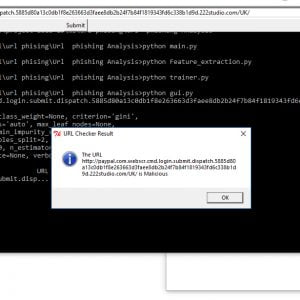
To prevent malware attacks, researchers and developers have proposed different security solutions, applying static analysis, dynamic analysis, and artificial intelligence. Indeed, data science has become a promising area in cybersecurity, since analytical models based on data allow for the discovery of insights that can help to predict malicious activities.?We can analyse cyber threats using two techniques, static analysis, and dynamic analysis, the most important thing is that these are the approaches to get the features that we are going to use in data science.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Demo with Explanation
Deliverables? : Project Files, Report and Presentation