

Description
Fake News Detection using Machine Learning
This Project comes up with the applications of Random Forest techniques for detecting the ‘fake news, that is, misleading news stories that come from non-reputable sources. Only by building a model based on a count vectorizer (using word tallies) or a (Term Frequency Inverse Document Frequency) TFIDF matrix, (word tallies relative to how often they are reused in other articles in your dataset) can only get you so far. But these models do not consider the important qualities like word ordering and context. It is very possible that two articles that are similar in their word count will be completely different in their meaning. The data science community has responded by taking action against the problem. There is a Kaggle competition called the Fake News Challenge? and Facebook is employing AI to filter fake news stories out of users’ feeds. Combatting fake news is a classic text classification project with a straightforward proposition. Is it possible for you to build a model that can differentiate between Realnews and Fake news So a proposed work on assembling a dataset of both fake and real news and employ a Random Forest classifier in order to create a model to classify an article into fake or real based on its words and phrases? Fake News Detection using Machine Learning
OBJECTIVE:
The main objective is to detect fake news, which is a classic text classification problem with a straightforward proposition. It is needed to build a model that can differentiate between Real news and Fake news.
INTRODUCTION:
These days fake news is creating different issues from sarcastic articles to fabricated news and planned government propaganda in some outlets. Fake news and lack of trust in the media are growing problems with huge ramifications in our society. Obviously, a purposely misleading story is fake news but lately blathering social media’s discourse is changing its definition. Some of them now use the term to dismiss the facts counter to their preferred viewpoints.
The importance of disinformation within American political discourse was the subject of weighty attention, particularly following the American presidential election. The term ‘fake news’ became common parlance for the issue, particularly to describe factually incorrect and misleading articles published mostly for the purpose of making money through page views. This paper, it is seemed to produce a model that can accurately predict the likelihood that a given article is fake news.
Facebook has been at the epicenter of many critiques following media attention. They have already implemented a feature to flag fake news on the site when a user sees it; they have also said publicly they are working on distinguishing these articles in an automated way. Certainly, it is not an easy task. A given algorithm must be politically unbiased ? since fake news exists on both ends of the spectrum? and also give equal balance to legitimate news sources on either end of the spectrum. In addition, the question of legitimacy is a difficult one. However, in order to solve this problem, it is necessary to have an understanding of what Fake News is. Later, it is needed to look into how the techniques in the fields of machine learning, and natural language processing help us to detect fake news.
Fake News Detection using Machine Learning
EXISTING SYSTEM:
There exists a large body of research on the topic of machine learning methods for deception detection, most of it has been focused on classifying online reviews and publicly available social media posts. Particularly since late 2016 during the American Presidential election, the question of determining ‘fake news has also been the subject of particular attention within the literature.
Conroy, Rubin, and Chen outline several approaches that seem promising towards the aim of perfectly classifying the misleading articles. They note that simple content-related n-grams and shallow parts-of-speech (POS) tagging have proven insufficient for the classification task, often failing to account for important context information. Rather, these methods have been shown useful only in tandem with more complex methods of analysis. Deep Syntax analysis using Probabilistic Context-Free Grammars (PCFG) has been shown to be particularly valuable in combination with n-gram methods. Feng, Banerjee, and Choi?[2]?are able to achieve 85%-91% accuracy in deception-related classification tasks using online review corpora.
Feng and Hirst implemented a semantic analysis looking at ‘object: descriptor’ pairs for contradictions with the text on top of Feng’s initial deep syntax model for additional improvement. Rubin, Lukoianova, and Tatiana analyze rhetorical structure using a vector space model with similar success. Ciampaglia et al. employ language pattern similarity networks requiring a pre-existing knowledge base.
Disadvantages:
- In the existing system, they classify the news, only based on the content-related n-grams and shallow part-of-speech. it’s hard to prove whether the news is fake or not by analyzing the tagging. even if the news is genuine it is detected as fake news
- it seems to be very complicated when genuine news is published on the social media
- failed to classify the valuable news
PROPOSED SYSTEM
In this paper, a model is built based on the count vectorizer or a Term Frequency Inverse Document Frequency (TF – IDF) matrix ( i.e ) word tallies relatives to how often they are used in other articles in your dataset can help. Since this problem is a kind of text classification, implementing a Random Forest classifier will be best as this is standard for text-based processing. The actual goal is in developing a model which was the text transformation (count vectorizer vs TF-IDF vectorizer) and choosing which type of text to use (headlines vs full text). Now the next step is to extract the most optimal features for count vectorizer or TF-IDF-vectorizer, this is done by using an n-number of the most used words, and/or phrases, lower casing or not, mainly removing the stop words which are common words such as the, when, and there and only using those words that appear at least a given number of times in a given test dataset.
ADVANTAGES
- in the proposed system, the news is classified according to the text that is continuously appeared in a news.
- we apply a random forest algorithm in our proposed system based on count vectorizer and TF-IDF vectorizer so the frequently used words are detected and removed and classified using random forest
- prediction accuracy will be higher compared to the existing system
COLLECTING DATA
So, there must be two parts to the data-acquisition process, fake news and real news. Collecting the fake news was easy as Kaggle released a fake news dataset consisting of 13,000 articles published during the 2016 election cycle. Now the latter part is very difficult. That is to get the real news for the fake news dataset. It requires huge workaround many Sites because it was the only way to do web scraping thousands of articles from numerous websites. With the help of web scraping a total of 5279 articles, real news dataset was generated, mostly from media organizations (New York Times, WSJ, Bloomberg, NPR, and the Guardian) which were published around 2015 – 2016.
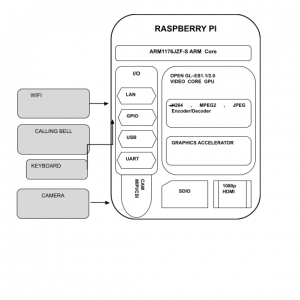
Block Diagram:

REQUIREMENTS
- Python
- NumPy
- pandas
- itertools
- matplotlib
- sklearn


































































































































































































































































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.