





Description
Intrusion Detection using Machine Learning
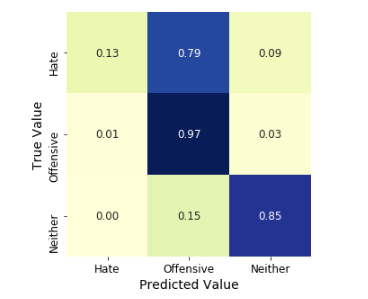
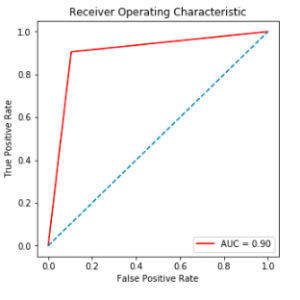
Recently, the huge amounts of data and its incremental increase have changed the importance of information security and data analysis systems for Big Data. An intrusion detection system (IDS) is a system that monitors and analyzes data to detect any intrusion in the system or network. The high volume, variety, and high speed of data generated in the network have made the data analysis process to detect attacks by traditional techniques very difficult. Big Data techniques are used in IDS to deal with Big Data for accurate and efficient data analysis processes. This paper introduced Spark?Chi? SVM model for intrusion detection. In this model, we have used ChiSqSelector for feature selection and built an intrusion detection model by using a support vector machine (SVM) classifier on Apache Spark Big Data platform. We used KDD99 to train and test the model. In the experiment, we introduced a comparison between Chi?SVM classifier and Chi?Logistic Regression classifier. The results of the experiment showed that Spark? Chi?SVM model has high performance, reduces the training time, and is efficient for Big Data.
EXISTING SYSTEM
There are many types of researches introduced for intrusion detection systems. With emerge of Big Data, the traditional techniques become more complex to deal with Big Data. Therefore, many researchers intend to use Big Data techniques to produce high-speed and accurate intrusion detection systems. In this section, we show some researchers that used machine learning Big Data techniques for intrusion detection to deal with Big Data. Used cluster machine learning technique. The authors used the k-Means method in the machine learning libraries on Spark to determine whether the network traffic is an attack or a normal one. In the proposed method, the KDD Cup 1999 is used for training and testing. In this proposed method the authors didn’t use the feature selection technique to select the related features.
PROPOSED METHOD
Spark Chi SVM
proposed model In this section, the researchers describe the proposed model and the tools and techniques used in the proposed method. Figure?1 shows the Spark-Chi-SVM model. The steps of the proposed model can be summarized as follows:
1 Load dataset and export it into Resilient Distributed Datasets (RDD) and Data Frame in Apache Spark.
2 Data preprocessing.
3 Feature selection.
4 Train Spark-Chi-SVM with the training dataset.
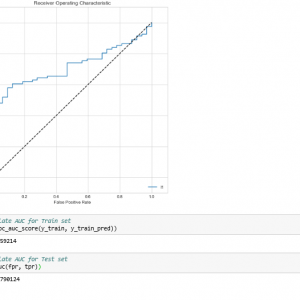
5 Test and evaluate the model with the KDD dataset.

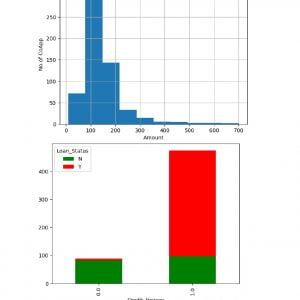
DATASET DESCRIPTION
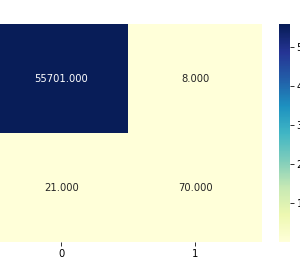
The KDD99 data set is used to evaluate the proposed model. The number of instances that are used is equal to 494,021. Does the KDD99 dataset have 41 attributes and the class attributes which indicates whether a given instance is a normal instance or an attack? The table provides a description of KDD99 dataset attributes with class labels.

SYSTEM REQUIREMENTS:
SOFTWARE REQUIREMENTS:
- Operating System | Windows 7, 8 and 10 (32 and 64 bit)
- Front End 😕 Python
- Packages 😕 numpy, Pandas, itertools, matplotlib,? sklearn, Spark
- Back End 😕 DataSet
2.3.2 HARDWARE REQIRQMENTS:
- Processor? ?- Dual Core
- Speed – 1 GHz
- RAM -? 4 GB
- Hard Disk? 200 GB
- Key Board? ?Standard Windows Keyboard
- Mouse? ?Two or Three Button Mouse
- Monitor -? SVG

























































































































































































































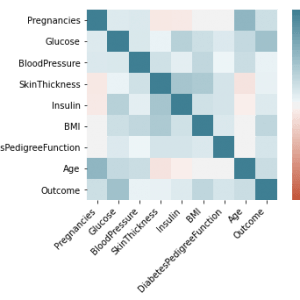



















































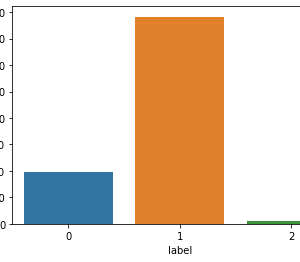





















































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.