




Description
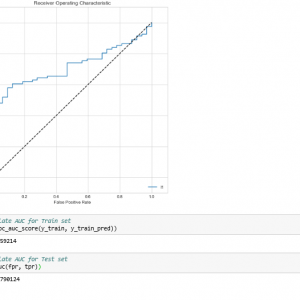
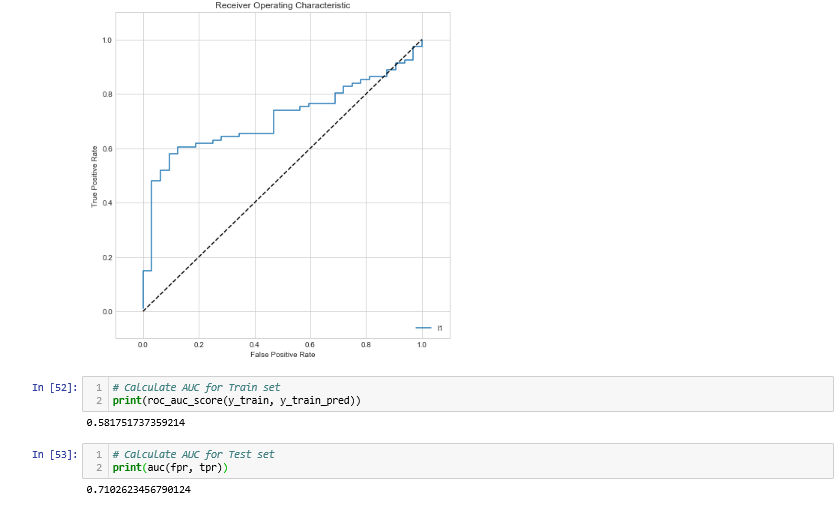
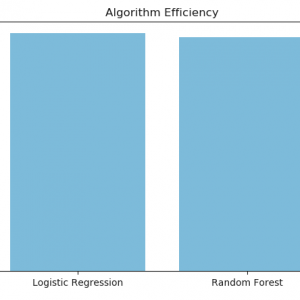
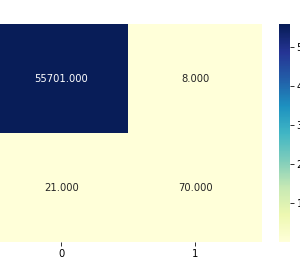
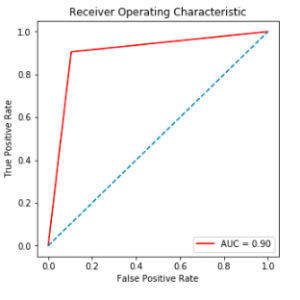
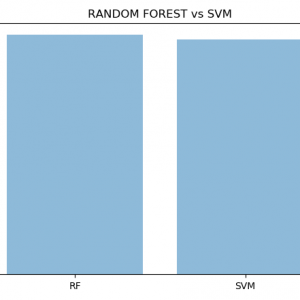
Our project mainly focused on credit card fraud detection in the real world initially. I will collect the credit card datasets for the trained dataset. Then will provide the user credit card queries for the testing data set. After the classification process of the random forest algorithm using the already analyzed data set and the user provides the current dataset. Finally optimizing the accuracy of the result data. Then will apply the processing of some of the attributes provided can find affected fraud detection in viewing the graphical model visualization. The performance of the techniques is evaluated based on accuracy, sensitivity, and specificity, precision. The results indicate about the optimal accuracy for Random Forest is 98.6% respectively. Credit Card Fraud Detection using Deep learning
Existing System:
In the existing System, research about a case study involving credit card fraud detection, where data normalization is applied before Cluster Analysis and with results obtained from the use of Cluster Analysis and Artificial Neural Networks on fraud detection has shown that by clustering attributes neuronal inputs can be minimized. And promising results can be obtained by using normalized data and data should be MLP trained. This research was based on unsupervised learning. The significance of this paper was to find new methods for fraud detection and to increase the accuracy of results. The data set for this paper is based on real-life transactional data by a large European company and personal details in data are kept confidential. The accuracy of an algorithm is around 50%. The significance of this paper was to find an algorithm and reduce the cost measure. The result obtained was 23% and the algorithm they find was Bayes minimum risk.
Disadvantage:
- In this paper, a new collative comparison measure that reasonably represents the gains and losses due to fraud detection is proposed.
- A cost-sensitive method that is based on Bayes minimum risk is presented using the proposed cost measure. Credit Card Fraud Detection using Deep learning
Proposed System:
In the proposed system, we are applying a random forest algorithm to classify the credit card dataset. Random Forest is an algorithm for classification and regression. Summarily, it is a collection of decision tree classifiers. The random forest has an advantage over the decision tree as it corrects the habit of overfitting to their training set. A subset of the training set is sampled randomly to train each individual tree and then a decision tree is built, each node then splits on a feature selected from a random subset of the full feature set. Even for large data sets with many features and data instances, training is extremely fast in random forests and because each tree is trained independently of the others. The Random Forest algorithm has been found to provide a good estimate of the generalization error and to be resistant to overfitting.
Advantage:
- Random forest ranks the importance of variables in a regression or classification problem in a natural way can be done by Random Forest.
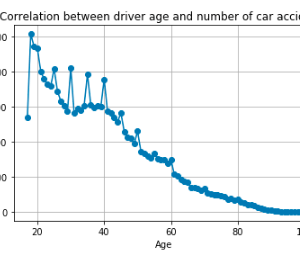
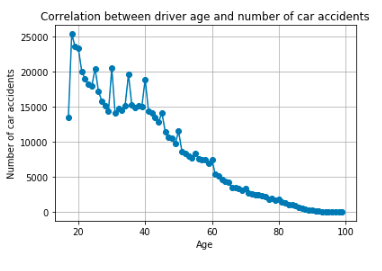
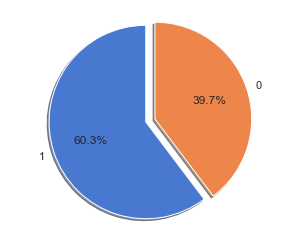
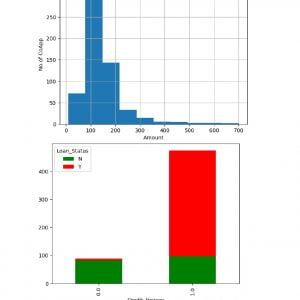
- The ‘amount’ feature is the transaction amount. Feature ‘class’ is the target class for the binary classification and it takes values 1 for positive case (fraud) and 0 for negative case (non-fraud).
System Architecture:

Software and Hardware Requirements:
Hardware:
- OS? Windows 7, 8, and 10 (32 and 64 bit)
- RAM? 4GB
Software:
- Python
- Anaconda












































































































































































































































































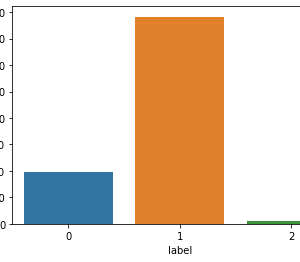





















































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.