






Description
Student feedback classification using Random Forest with ML
Abstract:
Advances in natural language processing (NLP) and educational technology, as well as the availability of unprecedented amounts of educationally-relevant text and speech data, have led to an increasing interest in using NLP to address the needs of teachers and students. Educational applications differ in many ways, however, from the types of applications for which NLP systems are typically developed. This paper will organize and give an overview of research in this area, focusing on opportunities as well as challenges. Student feedback classification using Random Forest with ML
Introduction:
Natural language processing (NLP) has over a 50-year history as a scientific discipline, with applications to education appearing as early as the 1960s. Initial work focused on automatically scoring student texts as well as on developing text-based dialogue tutoring systems, while later work also included spoken language technologies. While research in these traditional application areas continues to progress, recent phenomena such as big data, mobile technologies, social media, and MOOCs have resulted in the creation of many new research opportunities and challenges. Commercial applications already include high-stakes assessments of text and speech, writing assistants, and online instructional environments, with companies increasingly reaching out to the research community.1 as shown in Figure 1, NLP can enhance educational technology in several ways. As an example of the first role, NLP is being used to automate the scoring of student texts with respect to linguistic dimensions such as grammatical correctness or organizational structure. As an example of the second role, dialogue technologies are being used to achieve the benefits of human one-on-one tutoring – particularly in STEM domains – in a cost-effective and scalable manner. Examples of the third role include processing text from the web in order to personalize instructional materials to the interests of individual students, automating the generation of test questions for teachers, or (semi-) automating the authoring of an educational technology system. Given the increasing interest in applying natural language processing to education, communities have emerged that now sponsor regular meetings and shared tasks. Beginning in the 1990s, a series of tutorial dialogue systems workshops began to span the Artificial Intelligence and Education and the Natural Language Processing communities, including an AAAI Fall Symposium2. Since 2003, ten workshops on the ? Innovative Use of NLP for Building Educational Applications?3 have been held at the annual conference of the North American Chapter of the Association for Computational Linguistics. In 2006, the ? Speech and Language Technology in Education? 4 special interest group of the International Speech Communication Association was formed and has since organized six workshops5; members have also organized related special sessions at Interspeech conferences. Recent shared academic tasks have included student response analysis6 (Dzikovska et al. 2013), grammatical error detection7 (Ng et al. 2014), and prediction of MOOC attrition from discussion forums8 (Rose and Siemens 2014). There have also been highly visible competitions sponsored by the Hewlett Foundation in the areas of essay9 and short answer response10 scoring. Student feedback classification using Random Forest with ML
Student feedback classification using Random Forest with ML
Existing System:
Online computer science courses can be massive with numbers ranging from thousands to even millions of students. Though technology has increased our ability to provide content to students at scale, assessing and providing feedback (both for final work and partial solutions) remains difficult. Currently, giving personalized feedback, a staple of quality education
is costly for small, in-person classrooms and prohibitively expensive for massive classes. Autonomously providing feedback is, therefore, a central challenge for at-scale computer science education.
Disadvantage:
- This data provides the training set from which we can learn a shared representation for programs.
- To evaluate our program embeddings we test our ability to amplify teacher feedback.
Proposed System:
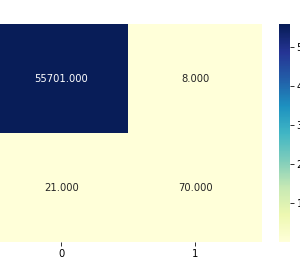
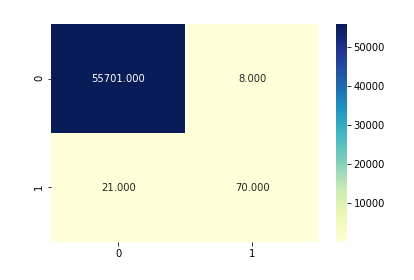
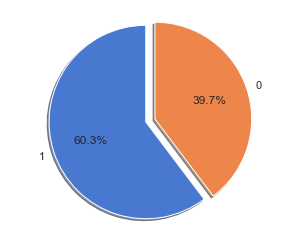
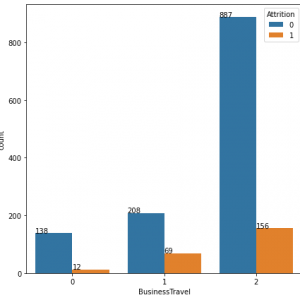
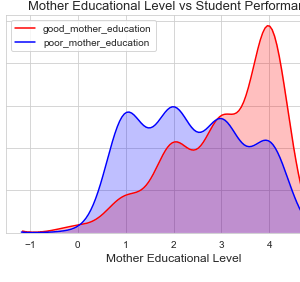
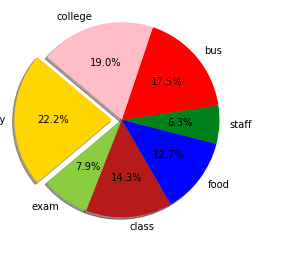
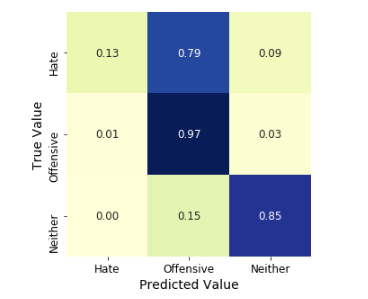
In the proposed methodology, we are collecting student feedback about the classroom, exam, and lab facilities. After that, we are predicting the dataset using natural language processing. In NLP, we are having the nltk tool kit. So we no need to use the training data for that. NLP segregates like a different group of feedback results. After predicting the data, we are analyzing positive, negative, and neutral. That results from we are making like 3 groups what are the department having positive and negative things from the dataset. Student feedback is collected in form of responses to questions in a single sentence; it requires sentiment analysis at the sentence level. In sentiment classification, machine learning methods have been used to classify each question as positive or negative. Testing of data is done based on a training model which is classified using a supervised learning algorithm. Evaluation of the total responses for every question and determine the polarity of feedback received in the context of the question. The evaluation of response is purely data-driven and hence simple while the classification of questions in form of natural language texts involves sentiment analysis.
Advantage:
- It is crucial to understand the patterns generated by the data like student feedback to effectively improve the performance of the institution and to create plans to enhance institutions? teaching and learning experience.
- Opinion Mining technique for classifying the students? feedback obtained during evaluation survey that is conducted every semester to know the feedback of students with respect to various features of teaching and learning such as module, teaching, assessments, etc.
- Student feedback improves communication between the lecturer and the students, allowing the lecturer to have an overall summary of the student?s opinion.
- 4GB or 8GB RAM
- Windows 10 32 or 64 bit
Software specification:
- Anaconda3
- Python
- Jupyter Notebook
Modules:

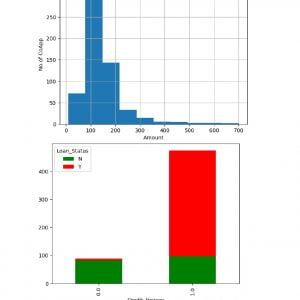
Dataset Collection:
In this phase, the data is prepared for the analysis purpose which contains relevant information. Pre-processing and cleaning of data are one of the most important tasks that must be done before the dataset can be used for machine learning. The real-world data is noisy, incomplete, and inconsistent. So, it is required to be cleaned.
Pre-Processing:
Raw feedback scraped from Twitter generally results in a noisy dataset. This is due to the casual nature of people?s usage of social media. Feedback has certain special characteristics such as Feedback, emoticons, user mentions, etc. which have to be suitably extracted. Therefore, raw twitter data has to be normalized to create a dataset that can be easily learned by various classifiers. We have applied an extensive number of pre-processing steps to standardize the dataset and reduce its size. We first do some general pre-processing on feedback which is as follows.
- Convert the tweet to lower case.
- Replace 2 or more dots (.) with space.
- Strip spaces and quotes (” and ?) from the ends of the tweet.
- Replace 2 or more spaces with a single space.
Extraction of Feature Set:
In this phase, the cleaned data that is obtained from the data preprocessing phase is used to obtain the feature sets or training data of the student feedback. When we train a classifier by taking maximum numbers of features, that contain all the irrelevant or redundant features can negatively affect the algorithm performance. So, it is required to carefully select the number and types of features that will be used to train the machine learning algorithms. Various feature selection techniques can be used for selecting features in the feature set/training data. Feature set or training data can be prepared from the cleaned data by using any of the available techniques like a bag of words, -gram, N-gram, POS, TOS tagging, etc. The training data can also be prepared by providing those labels and then dividing it into two classes like positive class and negative class. The feature sets and training set that have been obtained by using any of the above methods will be used for the implementation of machine learning algorithms.
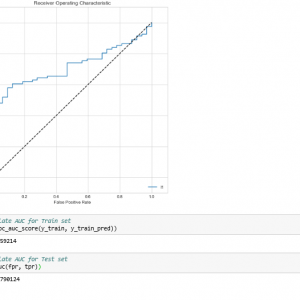
Testing on Datasets
Testing of data is done based on a training model which is classified using a supervised learning algorithm. Evaluation of the total responses for every question and determine the polarity of feedback received in the context of the question. The evaluation of response is purely data-driven and hence simple while the classification of questions in form of natural language texts involves sentiment analysis. To test the model, collected data from students who posted their views in online discussion forums.

Conclusion:
In this paper, we have presented a method for finding simultaneous embedding of preconditions and postconditions into points in shared Euclidean space where a program can be viewed as a linear mapping between these points. These embeddings are predictive of the function of a program, and as we have shown, can be applied to the tasks of propagating teacher feedback. The courses we evaluate our model on are compelling case studies for different reasons.


























































































































































































































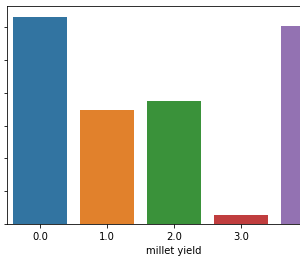
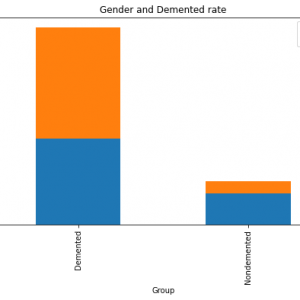



















































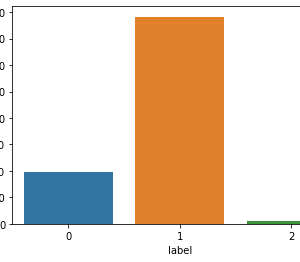




















































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.