

Description
Arabic is a Semitic language spoken by more than 330 million people as a native language, in an area extending from the Arabian/Persian Gulf in the East to the Atlantic Ocean in the West. Moreover, it is the language in which 1.4 billion Muslims around the world perform their daily prayers. Over the last few years, Arabic natural language processing (ANLP) has gained increasing importance, and several state of the art systems have been developed for a wide range of applications. The NLP techniques parse linguistic input (word, sentence, text, dialogue) according to the rules (derivational rules, inflectional rules, grammatical rules, etc.) and resources (like lexicon, corpus, and dictionary) of the target language. At the present time, this is at the stages of development especially for the English language. We expect that the current century will focus on NLP .After several decades of immense research on English NLP and other languages, Arabic Natural Language Processing (ANLP) have become a popular area of research, and some ANLP laboratory have been created .
EXISTING SYSTEM:
NADA is a New Arabic Dataset built from two existing Arabic corpora including OSAC and DAA datasets. This corpus followed a standard classification scheme (DDC) to provide a logical hierarchy presentation of classes. NADA corpus is composed of 10 categories, which achieved 5 classes from the first level of DDC and some classes from the second level.
DISADVANTAGES:
- NADA has? limitations concerning power, storage, and scalability that need to be addressed adequately. Integrating wireless sensor networks with the cloud.
- There is a lack of publicly available preprocessing and feature selection tools and reusable libraries for Arabic text documents.
PROPOSED SYSTEMS:
ANLP has become an exciting research domain. It involves the development of techniques and tools using the Arabic language. Numerous existing systems have been created for different applications such as machine translation, information retrieval and extraction, localization, and multilingual information retrieval systems. These applications encounter numerous intricate problems related to the structure and nature of the Arabic language.
ADVANTAGES:
- ML algorithms are used to automatically focus on common cases, whereas in the manual coding of rules, it is not clear where the effort must be directed.
- ML algorithms can produce models for unfamiliar data.
- ML can be accurate by merely increasing the input data, whereas systems based on the manual coding of the rules can be effective only if the complexity of the rules is increased, which is a much more challenging task
REFERENCE:
[1] A. Al-Ajlan, H. Al-Khalifa, and A. Al-Salman, ?Towards the Development of an Automatic Readability Measurements for the Arabic Language.? in Proceedings of the 3rd International Conference on Digital Media, 2008.
[2] P. C. Chang, M. Galley, and C. D. Manning, ?Optimizing Chinese word segmentation for machine translation performance,? in Proceedings of the third workshop on statistical machine translation, 2008, pp. 224-232.
[3] S. Sahu, B. Dongre, and R. Vadhwani, ?Web Spam Detection Using Different Features,? International Journal of Soft Computing and Engineering (IJSCE), 1(3), 2011.
[4] N. Boukhatem, ?The Arabic Natural Language Processing: Introduction and Challenges,? International Journal of English Language & Translation Studies, 2(3), pp. 106-112, 2014.
[5] A. Farghaly and K. Shaalan, ?Arabic natural language processing: Challenges and solutions,? ACM Transactions on Asian Language Information Processing (TALIP), 8(4), pp. 14, 2009.
[6] H. Hasanuzzaman, ?Arabic language: characteristics and importance. The Echo,? A Journal of Humanities &Social Science, 1(3), pp. 11-16, 2013.
[7] B. Babych and A. Hartley, ?Improving Machine Translation Quality with Automatic Named Entity Recognition,? in Proceedings of EACL-EAMT, 2003.
[8] H. Toda and R. Kataoka, ?A Search Result Clustering Method using Informatively Named Entities,? in Proceedings of the 7th ACM International Workshop on Web Information and Data Management, 2005.
[9] H. Abdelbaki, M. Shaheen, and O. Badawy, ?ARQA high performance Arabic question answering system,? in Proceedings of Arabic Language Technology International Conference (ALTIC), 2011.
[10] R. Florian, A. Ittycheriah, H. Jing, and T. Zhang, ?Named entity recognition through classifier combination,? in Proceedings of the seventh conference on Natural language learning at HLT-NAACL, Vol. 4, 2003, pp. 168-17.

























































































































































































































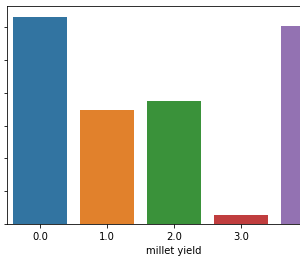








































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.