






Description
Hashtag Clustering using NLP | Machine Learning
Hashtags (single tokens often composed of natural language n-grams or abbreviations, prefixed with the character ?#?) are ubiquitous on social networking services, particularly in short textual documents (a.k.a. posts). Authors use hashtags to diverse ends, many of which can be seen as labels for classical NLP tasks: disambiguation (chips #futurism vs. chips #junkfood); identification of named entities (#sf49ers); sentiment (#dislike); and topic annotation (#yoga). Hashtag prediction is the task of mapping text to its accompanying hashtags. In this work, we propose a novel model for hashtag prediction and show that this task is also a useful surrogate for learning good representations of text. At last, we are predicting, the hashtag-based detailed query then we are showing the result as whether it will be positive or negative using SVM and random forest algorithm. Hashtag Clustering using NLP | Machine Learning
Hashtag Clustering using NLP | Machine Learning
Existing System:
In the existing system we show that our method outperforms existing unsupervised (word2vec) and supervised (WSABIE (Weston et al., 2011)) embedding methods, and other baselines, at the hashtag prediction task. We then probe our model’s generality, by transferring its learned representations to the task of personalized document recommendation: for each of M users, given N previous positive interactions with documents (likes, clicks, etc.), predict the N + 1 the document the user will positively interact with. To perform well on this task, the representation should capture the user’s interest in the textual content. We find representations trained on hashtag prediction outperform representations from unsupervised learning, and that our convolutional architecture performs better than WSABIE trained on the same hashtag task. Hashtag Clustering using NLP | Machine Learning
Disadvantage:
- It will ignore word order information, and so may have less modelling power than our approach.
- The text can hold acronyms like tfb, concatenated phrases like when or it can contain spelling mistakes.
- Due to Twitter slang particularities, even the most popular terms can be cryptic to users, and even more so to automatic text processing applications.
Hashtag Clustering using NLP | Machine Learning
Proposed System:
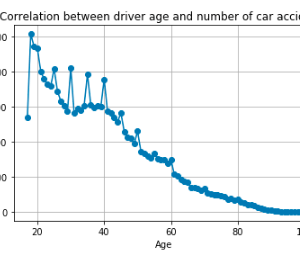
In the proposed work, we are applying 3 types of datasets like Twitter, Flickr, and YouTube. Then ask questions about the type of hashtag test data. It will predict a similar type of hashtag with a detailed description. Unsupervised word embedding methods train with a reconstruction objective in which the embedding is used to predict the original text. For example, word2vec tries to predict all the words in the document, given the embedding of surrounding words. We argue that hashtag prediction provides a more direct form of supervision: the tags are labeled by the author of the salient aspects of the text. Hence, predicting them may provide stronger semantic guidance than unsupervised learning alone. The abundance of hashtags in real posts provides a huge labeled dataset for learning potentially sophisticated models.

Advantage:
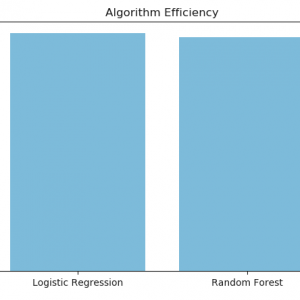
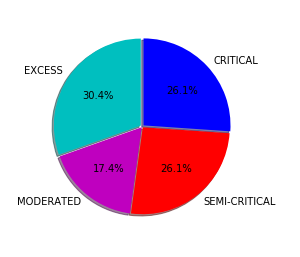
- The results of the clustering show that it is possible to identify semantically related hashtags.
- For each cluster, we extract the top terms, i.e. the most frequent terms in the virtual documents of the cluster.
- These top terms are the most representative for the cluster and fulfill their role as explanatory terms.
- We also extract top hashtags within a cluster; they are obtained by ranking all the hashtags in the cluster by an importance score.
Hashtag Clustering using NLP | Machine Learning
Block Diagram:

Hardware and Software Requirements:
Hardware:
- OS? Windows 7,8 or 10 (32 or 64-bit)
- RAM? 4GB
Software:
- Python IDLE
- Anaconda? Jupyter Notebook
Python Package:
- Numpy? Numerical Python
- Pandas? ?For Reading the Data
- Scikit-Learn
- NLTK Tool??For Pre-processing
- Algorithm Packages (Support Vector Machine and Random forest)
- Matplotlib
- Seaborn
Modules:
- Dataset Collection
- Pre-processing
- Clustering
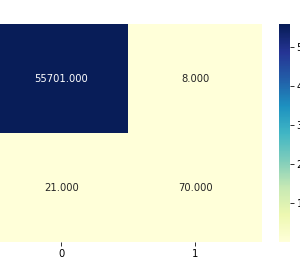
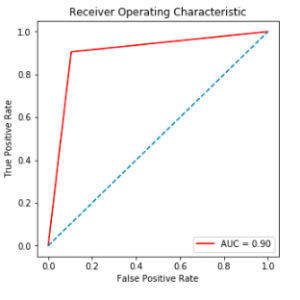
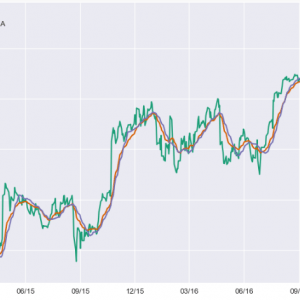
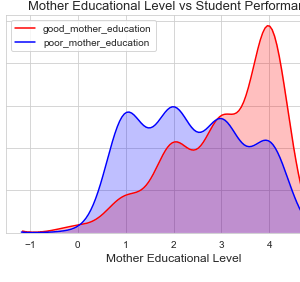
- Statistical Analysis














































































































































































































































































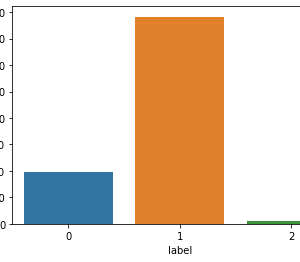


































































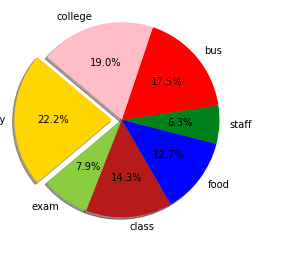
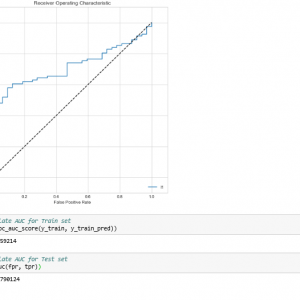
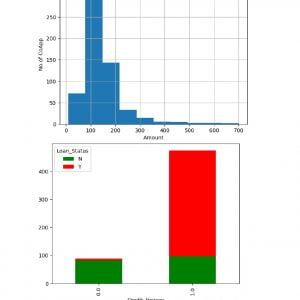
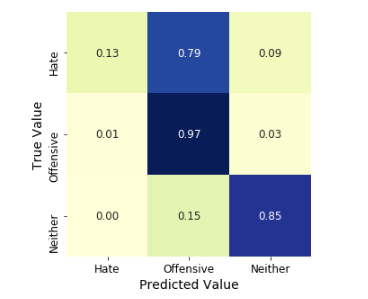


















































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.