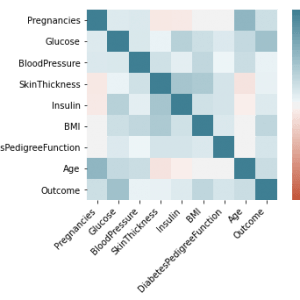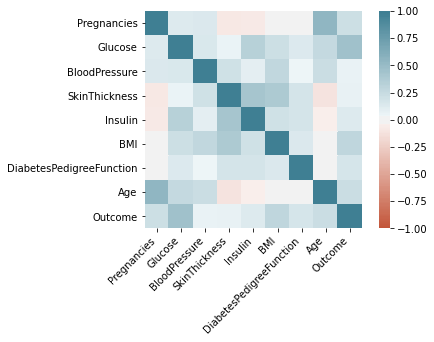The objective of the project is to understand the concepts of natural language processing and create a tool for text summarization. The concern in automatic summarization is increasing broadly so the manual work is removed. The project concentrates on creating a tool that automatically summarizes the document.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Live Session
Deliverables? : Project Files, Report and Presentation
Churn Modelling Analysis using Deep Learning | Machine Learning Projects
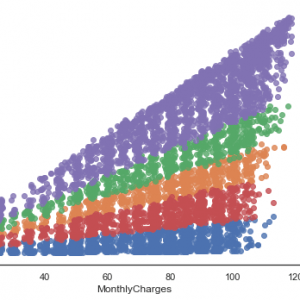
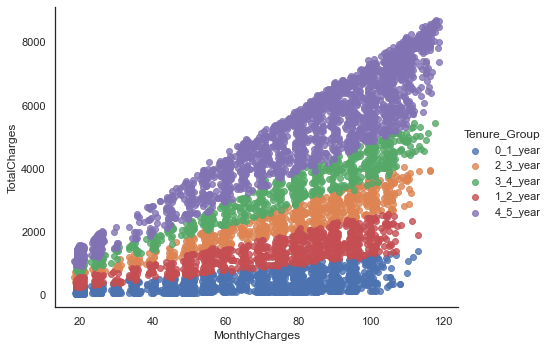
Churn Analysis is one of the worldwide used analyses on Subscription Oriented Industries to analyse customer behaviours to predict the customers which are about to leave the service agreement from a company. The proposed model ?rst classi?es churn customers data using classi?cation algorithms, in which the Random Forest (RF) and Decision tree (DT) algorithm performed well with 90.44% correctly classi?ed instances.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Live Session
Deliverables? : Project Files, Report and Presentation
The idea of visualizing data by applying machine learning and pandas in python. Taking dataset from a medical background of different people (prime Indians dataset from UCI repository). This data set consists of information on the user’s age, sex type of symptoms related to diabetes. Design a testing and training set and predict are chances of patients having diabetes in the coming five years. Data is classified and shown in the form of different graphs.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Live Session
Deliverables? : Project Files, Report and Presentation
We apply the ML model on datasets like Twitter, Flickr, and YouTube. It will predict a similar type of hashtag with a detailed description. Unsupervised word embedding methods train with a reconstruction objective, in which the embedding is used to predict the original text.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Demo with Explanation
Deliverables? : Project Files, Report and Presentation
The idea of visualizing data by applying machine learning and pandas in python. Taking dataset from a medical background of different people (prime Indians dataset from UCI repository). This data set consists of information on the user’s age, sex type of symptoms related to diabetes. Design a testing and training set and predict are chances of patients having diabetes in the coming five years. Data is classified and shown in the form of different graphs.
Platform? ? ? ? ?: Python
Delivery? ? ? ? ? :? One Day
Support? ? ? ? ? : Online Live Session
Deliverables? : Project Files, Report and Presentation