


Description
Customer Satisfaction Analysis NLP
Abstract:
Customer Satisfaction Analysis NLP – This paper’s goal is to use natural language processing to analyze customer happiness (NLP). From 2016 to 2019, we gathered more than 50,000 airline reviews using TripAdvisor data. Using data science techniques connected to NLP, this investigation illustrates the capability of detecting customers’ pain areas. Our research demonstrates that, in today’s world, data-driven decisions must be made swiftly in order to preserve customer happiness and avoid churn.
Introduction:
We are living in the instant era where customers are used to getting the best service for the shortest time available. This rule could be applied generally, but it is especially applicable to the airline industry where timing, service, and hospitality are out of immense value to the customers. Continuously increasing customer expectations makes it even more challenging to maintain high customer satisfaction. Besides, maintaining good customer satisfaction could potentially lead to increasing customer profitability [1]. Today, companies receive more customer feedback than ever before. Using apps like Twitter, Facebook, Instagram, and TripAdvisor at their fingertips, customers could post a review before they have even paid for the service. As such, customer reviews provide valuable insight into various areas of the business. Hence, the brand’s online reputation has the potential to either attract or deter new customers. Therefore, companies must take into consideration the received feedback and accordingly make changes in the company to improve the processes which caused complaints on the reviews. However, the problem that arises is how to effectively and efficiently analyze thousands of reviews which are often very long texts. It will be an extremely time-consuming task if it is to be managed by human employees. Consequently, we have applied a data science technique called natural language processing (NLP) [2] to help us with this task. NLP is a mix of language, machine learning, and artificial intelligence. The goal is to learn a computer to understand human language. The methodology is described comprehensively in the following sections.
The existing model of the system:
We have entered the era of Big Data as a result of recent significant advancements in computer memory, processing speed, and interconnectedness.
Because of the important information, such as ratings, complaints, and ideas, mining user-generated data for insights has become a popular topic among corporations. However, because of its noisy nature, this data is unorganized and thus underutilized. The goal of this study is to take data from TripAdvisor that is publicly available and turn it into knowledge.
Scraping is a data mining process used to obtain data. We were able to acquire publicly available TripAdvisor data from the Internet as a result of this. More than 50,000 airline reviews were gathered using the Python computer language and the Beautiful Soap package [3]. The three Middle Eastern airline firms, Etihad, Emirates, and Qatar Airways, were the focus of the investigation. These three were chosen mostly because they are located in a similar geographic area and compete for the same market, so the outcomes will be comparable.
Then, using the R programming language, NLP methods were used to extract meaningful information from the previously mentioned data. Text Mining is a type of Data Mining. Text mining techniques are often used for the following purposes:
- Topic Extraction – for example, recognizing the topic of a web article – sport, travel, economy, and so on [4, 5],
- Sentiment Analysis – utilized in web and social media monitoring to assess the writer’s attitude and emotional state (positive, negative, or neutral) [6],
- Market Intelligence – follow and analyze the market to extract the required information for firms to develop new strategies. For example, if Emirates launches a marketing campaign, Etihad receives the data immediately and can react promptly [7].
- Personalized Advertising – collecting insights from passengers’ preferences to present adverts in the appropriate location at the right time and for the right audience [8].
Proposed model of the system:
Customer Satisfaction Analysis using NLP – Data in the real world is often incomplete, loud, and inconsistent. As a result, before going on to the next stage of NLP, the following data pretreatment techniques [9] were used to assure excellent data quality:
Tokenization is the process of breaking down a text into tokens (single words)
- Elimination of English Stop-Words (and, or, to, the, etc.)
- Extra Filtering (may, usually, using, often, etc.)
- Stemming entails reducing words to their root forms, such as flying – fly, seats – seat, and so on.
System Architecture:

SOFTWARE AND HARDWARE REQUIREMENTS: –
HARDWARE:-
Processor: Intel i3
Hard Disk: 500 GB
RAM: 2 GB
Operating System: Windows7 or above
SOFTWARE:
Technology: Numpy, Matplotlib, Pandas, Seabron, Sklearn
IDE: Anaconda Navigator
Tool: Jupiter Notebook


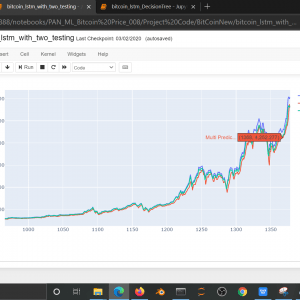

























































































































































































































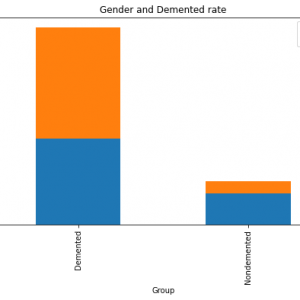


















































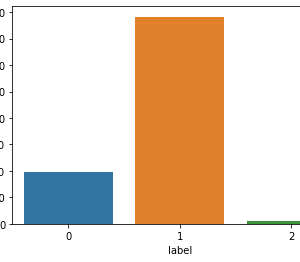
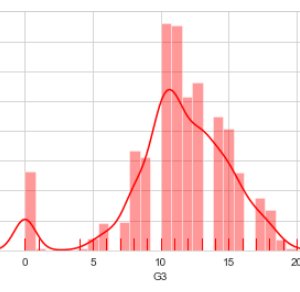

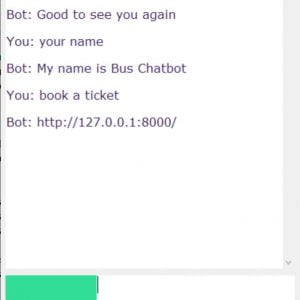
































































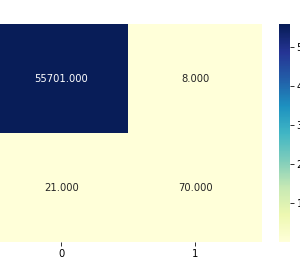

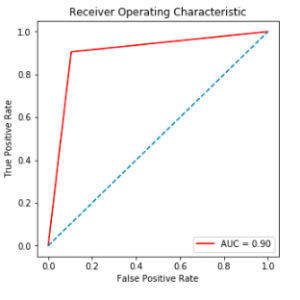
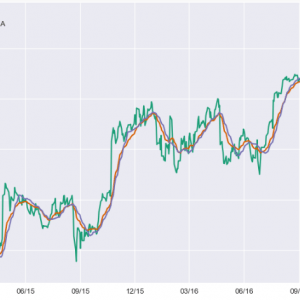
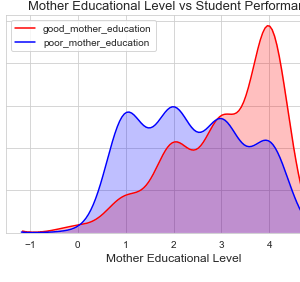
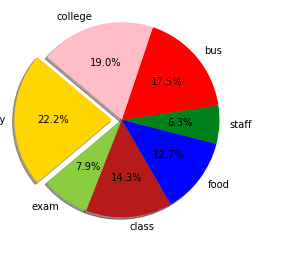
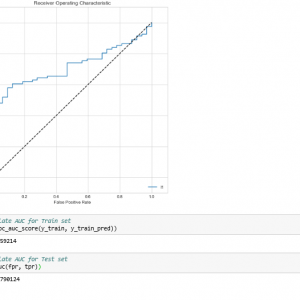
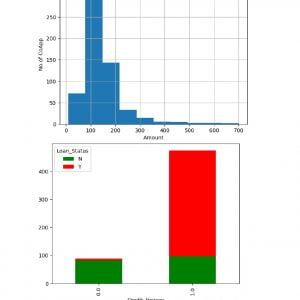
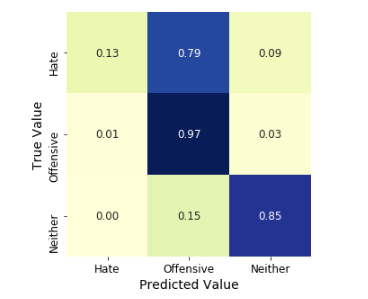
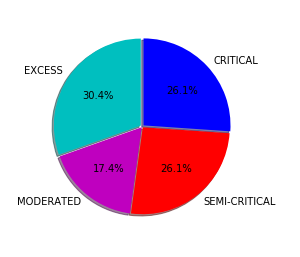
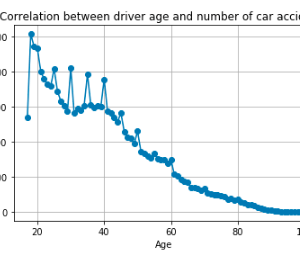



















































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.