

Description
Multifarious Data Processor In Network Security
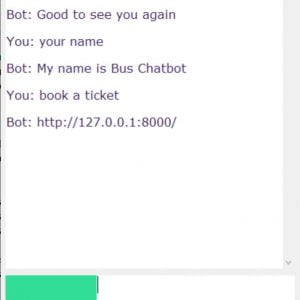
In this paper, we will create a dataset about college details like staff details and college events, functions,s, etc.? Then, first, we have to create one android app for using speech recognition. This paper presents the design and development of an intelligent voice recognition chatbot. The paper presents a technology demonstrator to verify a proposed framework required to support such a bot (a web service). So, using that Chabot android application, we can give speech input about college details. Then it will show the response as text information.? While a black-box approach is used, by controlling the communication structure, to and from the web service, the web service allows all types of clients to communicate to the server from any platform. The service provided is accessible through a generated interface that allows for seamless XML processing; whereby the extensibility improves the lifespan of such a service. By introducing an artificial brain, the web-based bot generates customized user responses, aligned to the desired character. Questions asked to the bot, which is not understood are further processed using a third-party expert system (an online intelligent research assistant), and the response is archived, improving the artificial brain capabilities for the future generation of responses. Multifarious Data Processor In Network Security
Multifarious Data Prossessor In Network Security
Existing method:
Conventionally web-bots exist; web-bots were created as text-based web friends and entertainers for a user. Furthermore, and separately there already exists enhanced rich site summary (RSS) feeds and expert content processing systems that are accessible to web users. Text-based web-bots can be linked to function beyond an entertainer as an informer, if linked with, amongst others, RSS feeds and or expert systems. Such a friendly bot could, hence, also function as a trainer providing realistic and up-to-date responses. Multifarious Data Processor In Network Security
Dragon speech recognition software is a Naturally Speaking Language. This software has three primary features of functionality.
- Dictation
- As the User dictates the words it will convert them into text and it displays
- Text-To-Speech
- And as text what is present or selected can be converted to speech.
- Command Input
- The user can control the operation by means of his voice without using a keyboard by just giving commands.
Disadvantage:
- Translation:
- It cannot translate from one language to another language here comes the translation problem.
- Untrained:
- It cannot work without training, training is required, and dynamic acceptance is not present.
Multifarious Data Processor In Network Security
Proposed System:
Speech recognition for the application Voice Message is done on a Google server, using the HMM algorithm. HMM, the algorithm is briefly described in this part. The process involves the conversion of acoustic speech into a set of words and is performed by a software component. Accuracy of speech recognition systems differs in vocabulary size and confusability, speaker dependence vs. independence, modality of speech (isolated, discontinuous, or continuous speech, read or spontaneous speech), and task and language constraints. A speech recognition system can be divided into several blocks: feature extraction, acoustic models database which is built based on the training data, dictionary, language model, and the speech recognition algorithm. Multifarious Data Prossessor In Network Security
Advantage:
- Speech recognition systems, based on hidden Markov models are today most widely applied in modern technologies.
- They use the word or phoneme as a unit for modeling.
- The model output is hidden probabilistic functions of state and can’t be deterministically specified.
- State sequence through model is not exactly known Multifarious Data Prossessor In Network Security
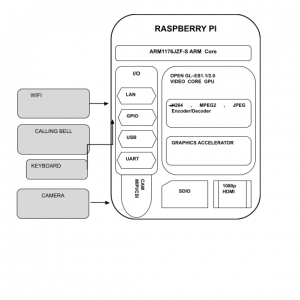
Hardware and Software Specification:
Hardware:
- OS? Windows 7,8 (32 or 64-bit)
- RAM? Min 2GB
Software:
- JDK
- Android Eclipse (ADT Bundle)
- Netbeans IDE
- Mysql and SQLyog.



































































































































































































































































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.