

Description
Twitter Data Classification
Abstract – Twitter Data Classification using Sentimental Analysis – Sentiment Analysis probes public opinion on user-generated content on the Web like blogs, social media, or e-commerce websites. The results of Sentiment Analysis are getting much attention with marketers that they are able to evaluate the success of an advertising campaign or the attitude of people on a new product launch. Business owners and advertising companies are using Sentiment Analysis to start new business strategies and to identify opportunities for new product development. The collected tweets were classified into positive, negative, and neutral sentiments. The machine learning classifier algorithms cross-validation were applied on the dataset and the results were tabulated for comparing and estimating which classifier algorithm yields the best accuracy. Other performance metric values like F Score, Precision, Recall were also calculated for comparison of various classifier performances on Sentiment Analysis. It was found that the ML method combined with K Fold cross-validation has produced the best accuracy in prediction. We have also applied the SetiStrength algorithm to find out the intensity or the strength of positive and negative comments from each sentence. With the help of the results in hand, we were able to predict the brand of mobile phone that was preferred in each country.
Existing System:
Existing methods primarily cast the problem as a supervised document classification task. These can be divided into two categories: one relies on manual feature engineering that is then consumed by algorithms such as SVM, Naive Bayes, and Logistic Regression the other represents the more recent deep learning paradigm that employs neural networks to automatically learn multi-layers of abstract features from raw data. The existing system was built using data mining techniques. In this method, they deal with small-level datasets. Here this system will have a very low accuracy score like 60 to 70 % only.
Disadvantage:
- Low-level data
- Low accuracy score
Proposed System:
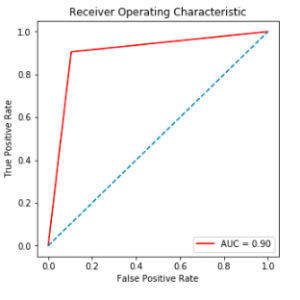
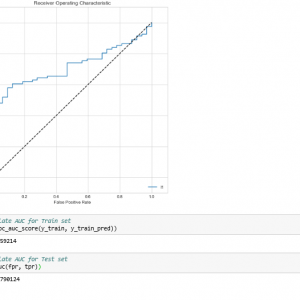
The proposed was implemented by machine learning techniques. Here we apply the classification algorithm for classification. Then we collect all the Twitter data’s from the internet. Using the data’s we extract all the future and get more numbers data’s also. So we apply the Logistic regression model to classify the values and we get a more accurate score like above 80%.
Advantage:
- Improve the accuracy score
- Deal with large amount dataset
System Architecture:

SOFTWARE REQUIREMENTS:
- Operating System: Windows 7, 8, and 10 (32 and 64 bit)
- Front End: Python
- Packages: NumPy, Pandas, matplotlib, Sklearn
HARDWARE REQUIREMENTS:
- Processor – Dual Core
- RAM – 2 GB or above
- Hard Disk – 100 GB or above
CONCLUSION:
Naive Bayes and SVM have supervised learning algorithms used to classify data according to parties. Most of the research has extracted only twitter data but we can also use other social media sites like Facebook and Instagram to fetch data. The data used so far is in the form of words and sentiment analysis is applied to it to determine the polarity of the word. But applying sentiment analysis to sentences may provide better results than on words. The final result can be obtained by comparing the Sentiment Percent of various political parties obtained by using the above algorithms.
REFERENCES
[1] J. Kaur, S. S. Sehra, and S. K. Sehra, ‘‘A systematic literature review of sentiment analysis,’’ Int. J. Comput. Sci. Eng., vol. 5, no. 4, pp. 22–28, 2017.
[2] M. Soleymani, D. Garcia, B. Jou, B. Schuller, S.-F. Chang, and M. Pantic, ‘‘A survey of multimodal sentiment analysis,’’ Image Vis. Comput., vol. 65, pp. 3–14, Sep. 2017, doi: 10.1016/j.imavis.2017.08.003.
[3] D. Vilares, M. A. Alonso, and C. Gómez-Rodríguez, ‘‘Supervised sentiment analysis in multilingual environments,’’ Inf. Process. Manage., vol. 53, no. 3, pp. 595–607, May 2017, doi: 10.1016/j.ipm.2017.01.004.
[4] O. Araque, I. Corcuera-Platas, J. F. Sánchez-Rada, and C. A. Iglesias, ‘‘Enhancing deep learning sentiment analysis with ensemble techniques in social applications,’’ Expert Syst. Appl., vol. 77, pp. 236–246, Jul. 2017, doi: 10.1016/j.eswa.2017.02.002.
[5] S. Wang and C. D. Manning, ‘‘Baselines and bigrams: simple, good sentiment and topic classification,’’ in Proc. 50th Annu. Meeting Assoc. Comput. Linguistics, vol. 2, Jeju Island, South Korea, 2012, pp. 90–94. [Online]. Available: http://dl.acm.org/citation.cfm?id=2390665.2390688















































































































































































































































































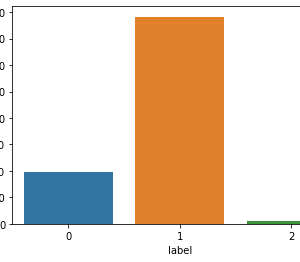




















































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.