Premium
Masterclass Courses

Associative
Certified Programs

Execlusive
Online Internships

Certified
Courses

Live Sessions
Mastermind Programs

Live Sessions
Project on Demand

MIcro Processor & Micro controller
Devlopment Boards

Trainer kIts & Drivers
Power Lab
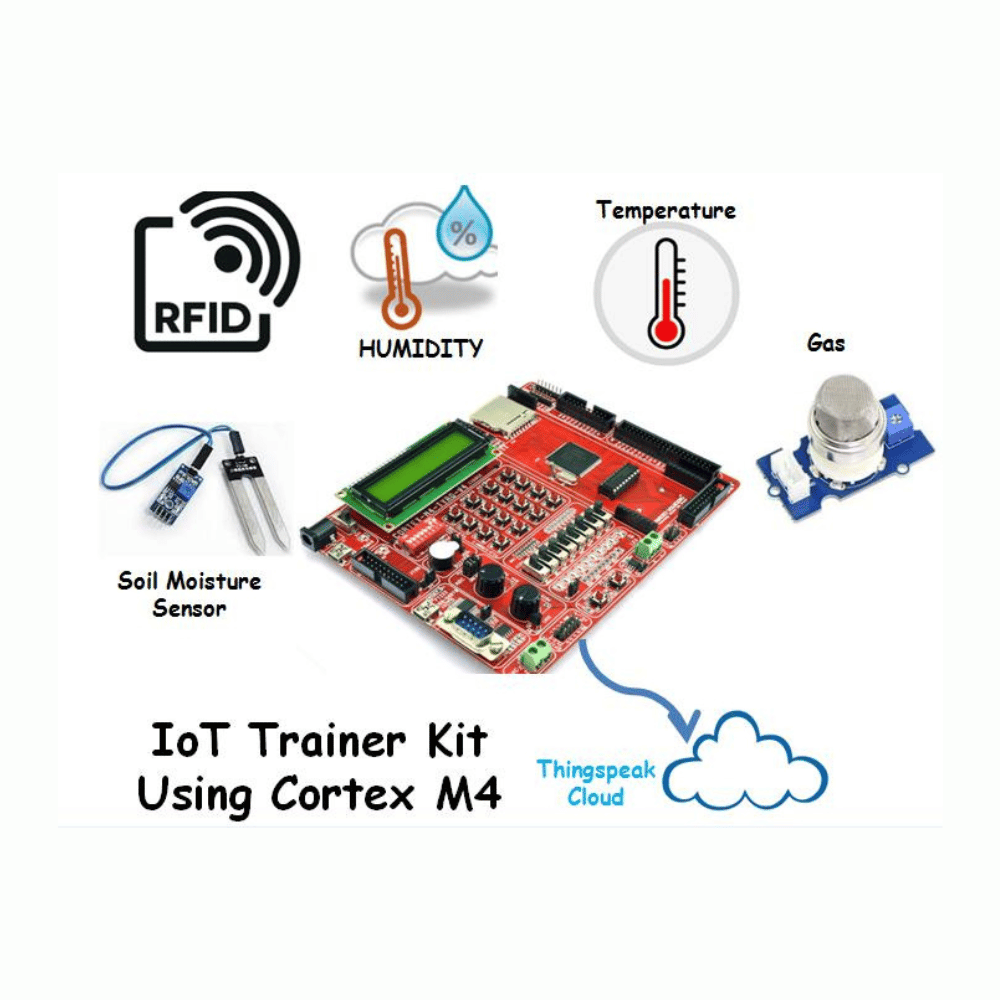
Sensor & Modules
Lab Trainer kits

Development board (Lab)
AI development board

Research and Development (R&D)
EV Prototype

Parashuram N Bannibagi
2023-11-20
Pantech eLearning conducting free certified masterclass, webinars on YouTube platform which will give ideas and makes you to learn more and paid self-paced learning with internship certificate.

Ravi Teja
2023-10-20
Amazing Python Internship Program offered by PantechELearning, great teaching by Mr. Philip Bedit & Shankar Sir. Special Thanks to Mr. Kumara Swamy. Thankyou so much for this amazing experience, thoroughly enjoyed the explanation #PhillipBedit #PantechELearning #PythonHandsOnInternship

electrical eee
2023-09-30
Session was good informative. could have added with present and future research areas.

Shambhu Nath Chaturvedi
2023-09-30
Nice

Shobana Velu
2023-09-23
I am Shobhan Palanivelu I studied computer science Engineering
This good place and improve my knowledge

Reshma Syed
2023-09-09
Very nice

Mohan Babu
2023-08-18
This is a good place to gain knowledge and teaching mentor are so friendly and genuine at teaching