






Description
To developed and implement a Machine learning approaches that characterizes the features of the Alzheimer , and? proposes a? Alzheimer processing model, from the machine learning perspective using Naive Bayes Classification? and Random forest. Alzheimer’s Disease Detection using Machine Learning
Alzheimer Disease Detection using Machine Learning
ABSTRACT
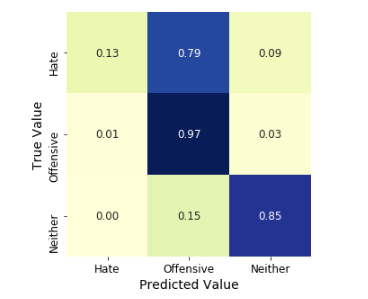
In that paper, we proposed as checking the whole patient Alzheimer using naive Bayes classification . Alzheimer?s? a? progressive? disease? that? demolishes brain?s? memory? and? its? regular functioning? as? well. There isn’t any single test till date to diagnose this disease and brain scans alone can?t determine whether the person is possessed by it. Currently, the physician believes that a person is affected by Alzheimer?s by based the reports of the family members about the behavioural tendencies and observations of the past medical history. AI combined with Machine Learning algorithms might now be able to change this situation. Big Data processing, as the information comes from multiple, heterogeneous, autonomous sources with complex and evolving relationships, and keeps growing. So in that, we will take results of how much percentage patients get disease as a positive information and negative information.? The?proposed shows a Bi processing model, from the data mining perspective. Using classifiers, we are processing Alzheimer percentage and values are showing as a confusion matrix.?We proposed a new classification scheme which can effectively improve the classification performance in?the situation that training dataset is available. In that dataset, we have nearly 500 patient details. We will get all that details from there. Then we will good and bad values are using naive Bayes classifier or Neural Network. Alzheimer Disease Detection using Machine Learning
EXISTING SYSTEM
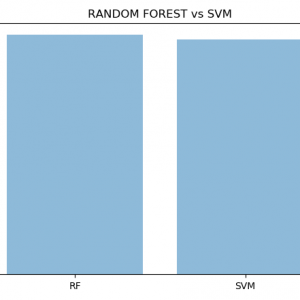
In this existing method is we used SVM Algorithm for predict? that Alzheimer? details. SVM algorithm makes only clustering process and it will segregate the person who are all suffering from Alzheimer. SVM Algorithm is slow process for classify all the given details. In that main disadvantage is time efficiency. Patient?s Alzheimer? details start with large-volume, heterogeneous, autonomous sources with distributed and decentralized control, and seek to explore complex and evolving relationships among data.
LIMITATIONS / DISADVANTAGES
- It will take more time to calculate our dataset which we having our Alzheimer dataset.
- Discover patterns using traditional data mining tools may not used for predictions.
- They concluded that drug treatment for patients in the young age group can be delayed whereas; patients in the old age group should be prescribed drug treatment immediately.
- Prediction and classification of various type of Alzheimer using classification algorithm was carried out in Alzheimer dataset
Alzheimer Disease Detection using Machine Learning
PROPOSED SYSTEM
The raw data set is given as input to the system. The unstructured voluminous input data can be obtained from various Electronic Health Record (EHR) / Patient Health Record (PHR), Clinical systems and external sources (government sources, laboratories, pharmacies, insurance companies etc.). Algorithms are Naive bayes classification, SVM algorithm, Decision tree, Random forest are used to predict the results accurately. To explore Big Data, proposed system analyzed several challenges at the data, model, and system levels. To support Big Data mining, high-performance computing platforms are required, which impose systematic designs to unleash the full power of the Big Data.
At the data level, the autonomous information sources and the variety of the data collection environments, often result in data with complicated conditions, such as missing/uncertain values. In other situations, privacy concerns, noise, and errors can be introduced into the data, to produce altered data copies.
ADVANTAGES
- Fastest path to business value from raw big data .
- Machine learning models to detect the Alzheimer early.
- Discover patterns using machine learning algorithm that identify the best mode of treatment for Alzheimer across different age.
- Novel, high value business insights driving growth and profitability
- Leverage existing skills and investments
- Minimal time, cost and effort spent
- These technical challenges are common across a large variety of application domains, and therefore not cost-effective to address in the context of one domain alone.
HARDWARE AND SOFTWARE SPECIFICATION
Hardware:
- 1 GB RAM
- 80 GB Hard Disk
- Intel Processor
- LAN
Software :
- Windows OS
- Python GUI or Anaconda Navigator
System Requirement:
Operating System: Windows 7 Ultimate 32 bit / Windows XP



























































































































































































































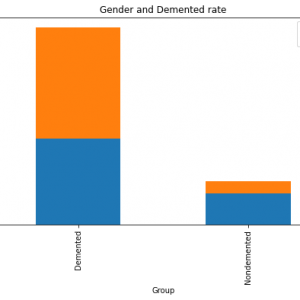




















































































































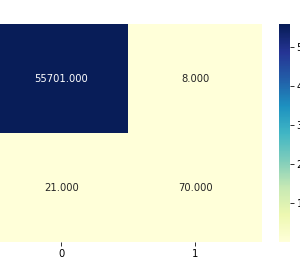

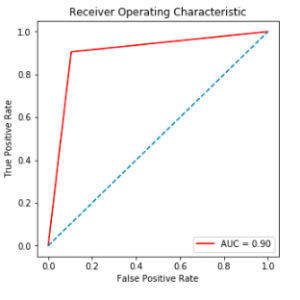


















































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.