

Description
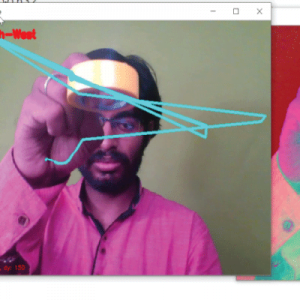
Hand Gesture Recogntion for Deaf and Dumb aid Communication
HRI represents a challenge to involve humans and robots interact. The problem is robot does not understand human? language directly and HRI requires media for communication which can be both understood by robot and easily done by human, especially to help deaf people, patient, and old people, therefore gesture recognition as communication media is needed to give order to Robot. Machine learning is a part of Artificial Intelligence (AI) which discusses the development of a system that depends on information or data This paper discusses hand gesture recognition as input using two methods, Fuzzy C Means clustering and decision K-Means clustering proposed the way to clustering some data which applying Euclidean idea of distance between all data elements. The method done by using feature extraction and feature matching concepts. We are going to these techniques and get clear output at the end of this project.
Hand Gesture Recogntion for Deaf and Dumb aid Communication
Introduction:
Challenge to involve humans and robots interact. The problem is robot does not understand human? language directly and HRI requires media for communication which can be both understood by robots and easily done by humans, especially to help deaf people, patients, and old people, therefore gesture recognition as communication media is needed to give order to robots. Machine learning is a part of Artificial Intelligence (AI) which discusses the development of a system that depends on information or data This paper discusses hand gesture recognition as input using two methods, Fuzzy C Means clustering and decision K-Means clustering proposed the way to clustering some data which applying Euclidean idea of the distance between all data elements. The method is done by using feature extraction and feature matching concepts. We are going to these techniques and get clear output at the end of this project.
Existing Systems
- Thresholding method
- PCA
- Edge detection
- Manual analysis – is time-consuming, inaccurate, and requires an intensively trained person to avoid diagnostic errors.
Drawback:
- Difficulties are there to find the optimal gradient
- Poor Edge detection.
- Manual segmentation
- Time-consuming
Proposed Systems
- Pre-processing
- Clustering
- Feature extraction
Advantages
- Better efficiency and less sensitive to noise
- Highly Security
- Automated? recognition and replication system.
- High accuracy
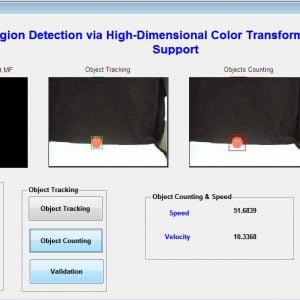
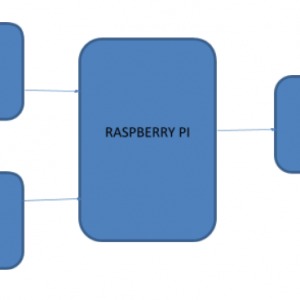
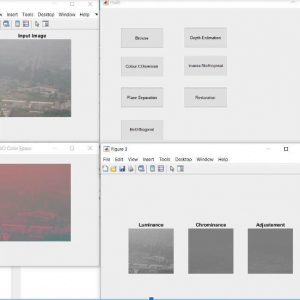
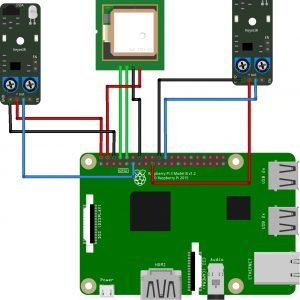
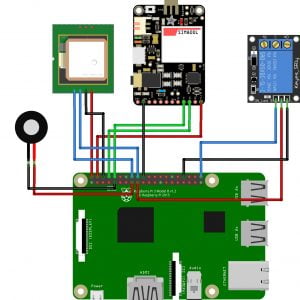
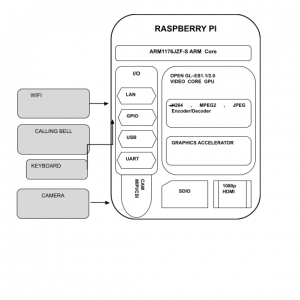
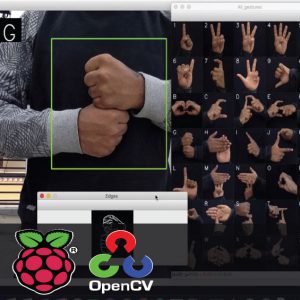
Block Diagram

Hand Gesture Recogntion for Deaf and Dumb aid Communication
Preprocessing:
Image Pre-processing? is a common name for operations with?images?at the lowest level of abstraction. Its input and output are intensity? images. The aim of?pre-processing?is an improvement on the? image? or data that suppresses unwanted distortions or enhances some images? features important for further processing.
Image restoration is the operation of taking a corrupted/noisy image and estimating the clean original image. Corruption may come in many forms such as motion blur, noise, and camera misfocus.? Image restoration is different from image enhancement in that the latter is designed to emphasize features of the image that make the image more pleasing to the observer, but not necessarily to produce realistic data from a scientific point of view. Image enhancement techniques (like contrast stretching or de-blurring by a nearest-neighbor procedure) provided by “Imaging packages” use no a priori model of the process that created the image.? With images, enhancement noise can be effectively removed by sacrificing some resolution, but this is not acceptable in many applications. In a Fluorescence Microscope resolution in the z-direction is as bad as it is. More advanced image processing techniques must be applied to recover the object.? De-Convolution is an example of an image restoration method. It is capable of Increasing resolution, especially in the axial direction removing noise and increasing contrast.
Hand Gesture Recogntion for Deaf and Dumb aid Communication
Clustering methods:
The K-means algorithm is an iterative technique that is used to partition an image into K clusters. The basic algorithm is:
- Pick K cluster centers, either randomly or based on some heuristic
- Assign each pixel in the image to the cluster that minimizes the variance between the pixel and the cluster center
- Re-compute the cluster centers by averaging all of the pixels in the cluster
- Repeat steps 2 and 3 until convergence is attained (e.g. no pixels change clusters)
In this case, variance is the squared or absolute difference between a pixel and a cluster center. The difference is typically based on pixel color, intensity, texture, and location, or a weighted combination of these factors. K can be selected manually, randomly, or by a heuristic. This algorithm is guaranteed to converge, but it may not return the optimal solution. The quality of the solution depends on the initial set of clusters and the value of K.
In statistics and machine learning, the k-means algorithm is a clustering algorithm to partition n objects into k clusters, where k < n. It is similar to the expectation-maximization algorithm for mixtures of Gaussians in that they both attempt to find the centers of natural clusters in the data. The model requires that the object attributes correspond to elements of a vector space. The objective tries to achieve is to minimize total intra-cluster variance, or, the squared error function. The k-means clustering was invented in 1956. The most common form of the algorithm uses an iterative refinement heuristic known as Lloyd’s algorithm. Lloyd’s algorithm starts by partitioning the input points into k initial sets, either at random or using some heuristic data. It then calculates the mean point, or centroid, of each set. It constructs a new partition by associating each point with the closest centroid. Then the centroids are recalculated for the new clusters, and the algorithm is repeated by alternate application of these two steps until convergence, which is obtained when the points no longer switch clusters (or alternatively centroids are no longer changed). Lloyd’s algorithm and k-means are often used synonymously, but in reality, Lloyd’s algorithm is a heuristic for solving the k-means problem, as, with certain combinations of starting points and centroids, Lloyd’s algorithm can in fact converge to the wrong answer. Other variations exist, but Lloyd’s algorithm has remained popular because it converges extremely quickly in practice. In terms of performance, the algorithm is not guaranteed to return a global optimum. The quality of the final solution depends largely on the initial set of clusters, and may, in practice, be much poorer than the global optimum. Since the algorithm is extremely fast, a common method is to run the algorithm several times and return the best clustering found. A drawback of the k-means algorithm is that the number of clusters k is an input parameter. An inappropriate choice of k may yield poor results. The algorithm also assumes that the variance is an appropriate measure of cluster scatter.
Feature extraction:
- In machine learning, pattern recognition, and? image processing,?feature extraction starts from an initial set of measured data and builds derived values (features) intended to be informative and non-redundant, facilitating the subsequent learning and generalization steps.
- This method is commonly used to get clear features like veins in fingers, and face mark points these are all used to get more information about the input. After this process, we can get a clear idea about the given image/video. Even though videos are also taken frame by frame so that the process act on the videos also. Then only we can be able to classify the input to the dataset.
- After getting features from an image the whole features are matched by the feature matching concept. This is the main concept in this artificial model.
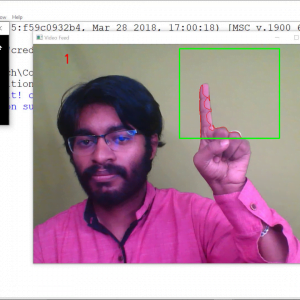
- Feature matching is a necessary step to get a gestured recognition at the end of the project or else output. The given input video contains the gestured images these are all classified by using the feature matching concept
Requirement Specifications
Hardware Requirements
- system
- 4 GB of RAM
- 500 GB of Hard disk
SOFTWARE REQUIREMENTS:
- Python Idle
- Library Packages
Hand Gesture Recogntion for Deaf and Dumb aid Communication
Reference:
[1] J. Han and M. Kamber, Data Mining Concepts and Techniques, United States of America, 2001.
[2] S.Cheng, C. Hsu, and J. Li, “Combined Hand Gesture-Speech Model for Human Action Recognition,” in Sensors, vol 13, 2013.
[3] P. Fankhauser, M. Bloesch, and D.Rodriguez, “Kinect v2 for Mobile Robot Navigation?: Evaluation and Modeling,” in Advanced Robotics (ICAR), International Conference on. IEEE, 2015., 2015.
[4] V. Vapnik, The Nature of Statistical Learning Theory, New York: Springer-Verlag, 1995.
[5] J.C.Platt, N. Cristianini, J. Shawe-Taylor, “Large margin dags for multiclass classification.,” in Advances in Neural Information
Processing Systems, 2000.
[6] S. P. Lloyd, “Least square quantization in PCM,” in IEEE
Transactions on Information Theory.,2002.
[7] Chiu RWK, Chan KCA, Gao Y, Lau VYM, Zheng W, et al. (2008). Noninvasive prenatal diagnosis of fetal chromosomal aneuploidy by massively parallel genomic sequencing of DNA in maternal plasma. Proc Natl Acad Sci U S A 105: 20458-20463.



































































































































































































































































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.