

Description
Objective: –
The purpose of machine learning is?to discover patterns in your data and then make predictions based on often complex patterns to answer business questions, detect and analyze trends and help solve problems.
Failure Prediction of Machineries using Machine Learning
Abstract: –
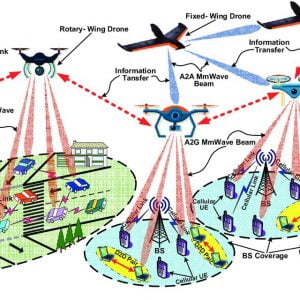
One of the key issues facing the development of future generation wireless systems is providing dependable broadband wireless communications in high mobility situations, such as high-speed railway systems. This study offers a thorough examination of high-mobility communications. We begin by presenting a list of important challenges and opportunities in high-mobility communication systems, followed by in-depth evaluations of strategies that can handle these issues and take use of the unique potential. The review includes accurate modelling of high mobility channels, transceiver structures that can exploit the properties of high mobility environments, signal processing techniques that can harvest the benefits (e.g., Doppler diversity) and mitigate the impairments (e.g., carrier frequency offset, intercarrier interference, channel estimation errors) in high mobility systems, and mobility management.
The survey focuses mostly on physical layer activities, which are the ones most influenced by the mobile environment, with some consideration of upper layer operations, such as handover management and control-plane/user-plane decoupling, which are critical to high mobility operations. The paper concludes with a summary of future research directions in high mobility communications. Failure Prediction of Machineries using Machine Learning
Introduction: –
Given the large deployment of high-speed railway (HSR) systems, as well as the growing popularity of highway vehicular communications systems and low-altitude flying object (LAFO) systems, wireless communications in high-mobility situations have gotten a lot of attention in recent years. The fifth-generation (5G) communications system includes high mobility communications as a standard feature. At a data rate of 150 Mbps or higher, 5G systems are expected to provide simultaneous internet services to a large number of customers travelling at speeds up to 500 km/hr, the maximum speed feasible by HSR systems. For LAFO systems, the relative speed between transmitter and receiver can be on the order of 1000 km/hr or more.
Existing Model of System: –
A survey report summarises a number of studies on software fault proneness prediction that used a variety of machine learning approaches on various datasets and metrics. A total of 56 studies were found to have used logistic regression. Following that came Naive Bayes, which was employed in 33 research. Ten research employed the J48 decision tree approach. The most accurate method was Naive Bayes, with logistic regression coming in second. The study also found that studies that used static code metrics and change measurements were more accurate than studies that solely used static code metrics.
In research, the logistic regression approach was employed. Their models were created as explanatory models rather than prediction models. As a result, they did not assess the model’s accuracy. Instead, they reported the model’s quality of fit. Moser et al. looked into the differences between employing change and static code metrics. Their findings revealed that change measurements outperform static code metrics as predictors. On data from Eclipse releases, they used logistic regression, Naive Bayes, and decision tree J48 methods (i.e., 2.0, 2.1 and 3.0). They also tested the three algorithms in three different scenarios: solely using change metrics, only using static code metrics, and a combination of both static code and change measurements.
Proposed Model of System: –
The datasets, measurements, and machine learning classifiers used to forecast software fault proneness are briefly described in this section. The data for this investigation was taken from our previous studies. Employed both static code metrics and change metrics. In above, however, only change metrics were used. The features derived from Eclipse source files are comparable to those found in given data.
The features of software source code are captured by static code metrics. The lines of code metre, which is defined as the total amount of source code lines utilised in a file, is the earliest example of static code metrics. Other factors to consider are the number of classes in a file, the number of methods, and the complexity of the code. The change process that occurred to a file is captured by change metrics. They contain things like the number of revisions, bug patches, and the amount of lines added or removed from a file.

Description: –
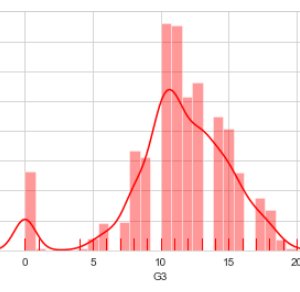
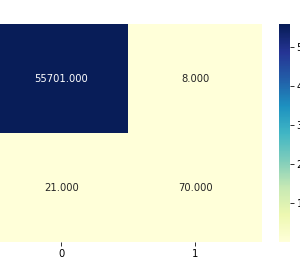
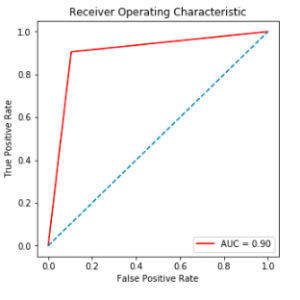
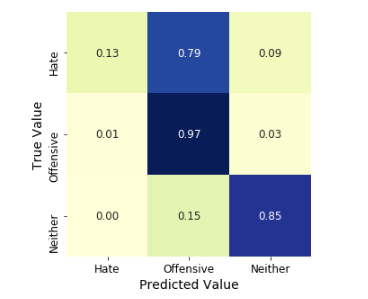
The results of utilizing the three machine learning classifiers are shown in this section. We apply the three methods to a variety of circumstances, depending on the metrics we use in our classifiers. Tables 5, 6, and 7 show the results of all classifiers with all sets of measurements. In all tables, the grey cells represent the superior performance (highest PC, TPR, and G, and lowest FPR) for each classifier in each dataset. The reduced set of change metrics detected in given data is our first set of metrics. The change metrics are the second set. The static set is the third Metrics for code Finally, we employ a hybrid of static code measurements and change metrics. We compare the findings and present the accuracy, recall, false positive rate, and G score of each model based on the confusion matrix outcome
System Requirements: –
- Hardware
OS ? Windows 7, 8 and 10 (32 and 64 bit)
RAM ? 4GB
- Software:
Python
Anaconda navigator
Python built-in modules












































































































































































































































































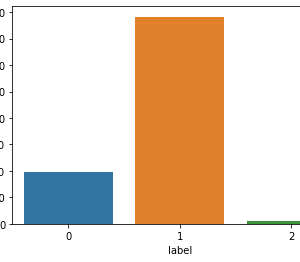









































































































































































































































































































































































































































































































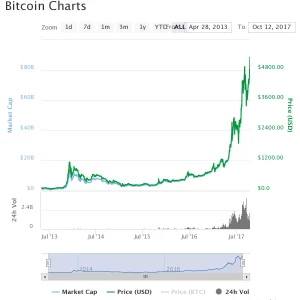












































































































Customer Reviews
There are no reviews yet.