

Description
Election Result Prediction based on Twitter Data Analysis using AI
Objective: – Election Result Prediction based on Twitter Data Analysis using AI – The goal of this project is to build a predictive model to predict the outcomes of elections before the elections were held.
Abstract: –
Democracy is a form of government in which citizens elect their own leaders. Elections are held on a regular basis in our country, India, to elect a political leader. People nowadays prefer to know who will win an election ahead of time. They make predictions based on the news, personal conversations, and online platforms. Facebook, Twitter, and WhatsApp have all become popular in recent years. These social networking services are accessible to everyone with an internet connection.
The opinions, news, and discussions available on these platforms aid in the prediction of results. These are the places where one can express oneself on the internet. Twitter is one such network that becomes popular in our country following major events. On Twitter, anything that is news becomes a trend. People express their opinions, their anger, and their campaigns against any political party, figure, or leader. Predicting election results before exit polls are quite useful. As a result, this study examines tweets gathered from Twitter and uses emotional analysis to forecast election outcomes.
Introduction: –
Sentimental Analysis is a technique for teaching a computer to extract emotion from the text. A text can be anything, whether a basic review, a social statement, tweets, or text message. On digital platforms, a substantial amount of high-value and diverse social data has been accumulated. This large amount of social data might be computationally processed and analyzed to learn about people’s preferences and affinities with any subject.
When people’s opinions on social media platforms are processed and analyzed, they can be utilized to forecast outcomes that are valuable in business and other areas of life.
Existing Model of System: –
There has been a lot of study on utilizing machine learning models for emotive analysis to forecast election results. For predicting election results in diverse places around the world, researchers have utilized everything from rudimentary machine learning models to advanced deep learning algorithms. Studies on election prediction have been conducted since the early 2000s, and numerous methodologies and researches have been proposed. The popularity of tweets was used to forecast the outcome of the 2017 French elections. Their model, however, was only relevant to tweets in French. further explained how a multiclass classification of two political groups or parties can be done on tweets connected to them and compared to determine a winner. I worked on Twitter trends connected to the president’s performance. He employed a lexicon-based methodology to extract strong sentiments from Twitter data linked to elections and used a date-time series method to forecast the final outcome.
Using a sentiment analyzer, we categorized tweets and stored them in MongoDB. Rather than focusing on certain parties, the writers used tweets from all of the candidates in the election.
This study examines the 2019 Indian Lok Sabha election and converts the problem of unsupervised learning to supervised learning using a Python tool called VADER, as well as various machine learning models and two feature extraction strategies.
Proposed Model of System: –
Election Result Prediction – The main approach of this paper is to convert an unsupervised problem to a supervised learning problem and then perform sentimental analysis on the data followed by visualization and prediction of results.
- Dataset Collection and Cleaning
- Splitting of the dataset and Applying VADER
- Model Training
- Logistic Regression
- Decision Tree
- Naive-Bayes
- LinearSVC
- XGBoost
System Architecture: –

Conclusion: –
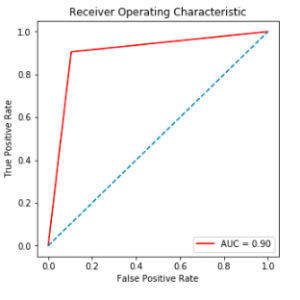
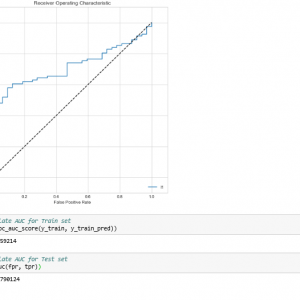
On a 64-bit processor, the election forecast for the Lok Sabha elections of 2019 was done using the free source web application “Jupyter Notebook.” Using “tweeps” and Github, a dataset including 41,265 total tweets from the BJP and Congress was created. The dataset includes columns for location, time, the party to which the tweet belongs, and the entire tweet. For this study, the columns of the entire tweet, as well as their party, are considered. Both sides’ neutral tweets were ignored because they had no impact on the final outcome. Exhibit the accuracies of five machine learning techniques paired with the BOW feature extraction technique. With Logistic Regression, the BOW model has an accuracy of 81.7 percent, 84.5 percent with XGBoost, 86.0 percent with Decision Tree, 79.4 percent with Naive-Bayes, and 82.2 percent with LinearSVC. Among all combinations of models with BOW, the Decision Tree with BOW has the highest accuracy.
System Requirements: –
Hardware
- OS – Windows 7, 8, and 10 (32 and 64 bit)
- RAM – 4GB
Software:
- Python
- Anaconda navigator
- Python built-in modules
References: –
[1] A. Sarlan, C. Nadam, and S. Basri, “Twitter sentiment analysis,” in Proceedings of the 6th International conference on Information Technology and Multimedia, pp. 212–216, IEEE, 2014. [2] P. Lai, “Extracting strong sentiment trends from twitter,” 2010
[3] A. Tumasjan, T. O. Sprenger, P. G. Sandner, and I. M. Welpe, “Predicting elections with twitter: What 140 characters reveal about political sentiment,” in Fourth international AAAI conference on weblogs and social media, Citeseer, 2010.
[4] P. Salunkhe and S. Deshmukh, “Twitter based election prediction and analysis,” International Research Journal of Engineering and Technology (IRJET), vol. 4, p. 10, 2017.
[5] F. Nausheen and S. H. Begum, “Sentiment analysis to predict election results using python,” in 2018 2nd international conference on inventive systems and control (ICISC), pp. 1259–1262, IEEE, 2018.
[6] A. Harb, M. Planti, G. Dray, M. Roche, Fran, o. Trousset, and P.Poncelet, “Web opinion mining: how to extract opinions from blogs?,” presented at the Proceedings of the 5th internationalconference on Soft computing as transdisciplinary scienceandtechnology, Cergy-Pontoise, France, 2008.
[7] M. Taboada, J. Brooke, M. Tofiloski, K. Voll, and M. Stede,”Lexiconbased methods for sentiment analysis,” Comput. Linguist., vol. 37, pp. 267-307, 2011.
[8] Q. Wu and S. B. Tan, “A two-stage framework for crossdomainsentiment classification,”Expert Systems with Applications, vol.38, pp. 14269-14275, Oct 2011.



































































































































































































































































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.