

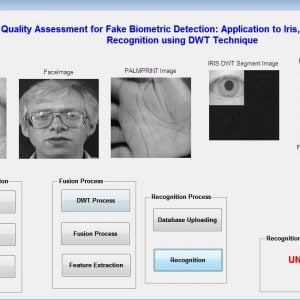
Description
Dielectric Rectangular Resonator Antenna
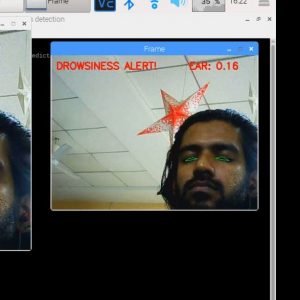
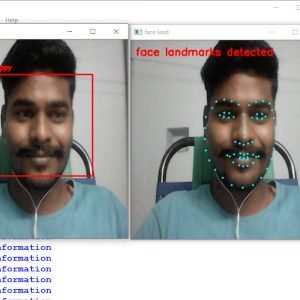
Objective: The objective of this project is to recognize and annotate human action in an unconstrained environment, where the images contain a huge range of variability.
Given a video sequence, the task of action recognition is to identify the most similar action among the action sequences learned by the system. Such human action recognition is based on evidence gathered from videos. It has wide applications including surveillance, video indexing, biometrics, telehealth, and human-computer interaction. Vision-based human action recognition is affected by several challenges due to view changes, occlusion, variation in execution rate, anthropometry, camera motion, and background clutter. In this survey, we provide an overview of the existing methods based on their ability to handle these challenges as well as how these methods can be generalized and their ability to detect abnormal actions. Such systematic classification will help researchers to identify the suitable methods available to address each of the challenges faced and their limitations. In addition, we also identify the publicly available datasets and the challenges posed by them. From this survey, we draw conclusions regarding how well a challenge has been solved, and we identify potential research areas that require further work. Dielectric Rectangular Resonator Antenna
Dielectric Rectangular Resonator Antenna
Existing Method:
- Appearance-based methods involve LDA
- Geometric methods.
Drawbacks
- In appearance-based methods, less accurate features description because of whole image consideration
- In geometric-based methods, geometric features like the distance between eyes, face length, width, etc., are considered which do not provide optimal results
Dielectric Rectangular Resonator Antenna
Proposed Method
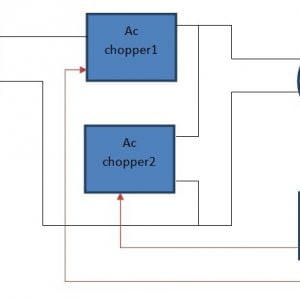
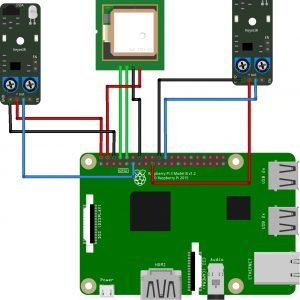
Block diagram
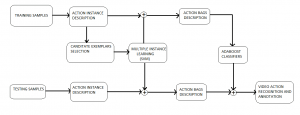 Dielectric Rectangular Resonator Antenna
Dielectric Rectangular Resonator Antenna
Methodologies
- Adaboost Classifiers
- HOG
- SVM
Advantages
- Detecting accuracy is high due to extracting local features of the image
- The geometric features like the distance between eyes, face length, width, etc., are considered which provides high optimal results
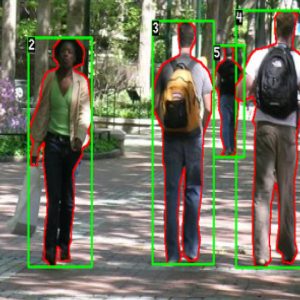
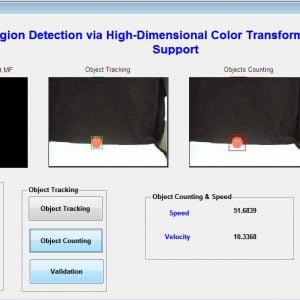
Applications
- Queue forming
- People counting
Software Required
- MATLAB 7.5 and above versions
References
[1] P. Ekman and W. V. Friesen, ?Facial action coding system,? 1977.
[2] J. Hager, P. Ekman, and W. Friesen, ?Facial action coding system. salt lake city, ut: A human face,? ISBN 0-931835-01-1, Tech. Rep., 2002.
[3] Z. Zhang,?Feature-based facial expression recognition: Sensitivity analysisandexperimentswithamultilayerperceptron,?International journal of pattern recognition and Arti?cial Intelligence, vol. 13, no. 06, pp. 893? 911, 1999. [4] G. Guo and C. R. Dyer,?Simultaneous feature selection and classic?er training via linear programming: A case study for facial expression recognition,? in Computer Vision and Pattern Recognition, 2003. Proceedings. 2003 IEEE Computer Society Conference on, vol. 1. IEEE, 2003, pp. I? 346.
[5] M. F. Valstar, I. Patras, and M. Pantic, ?Facial action unit detection using probabilistic actively learned support vector machines on tracked facial point data,? in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR? 05)-Workshops. IEEE, 2005, pp. 76? 76.
[6] M. Valstar and M. Pantic, ?Fully automatic facial action unit detection and temporal analysis,? in 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW? 06). IEEE, 2006, pp. 149? 149.
[7] C. Shan, S. Gong, and P. W. McOwan, ?Facial expression recognition based on local binary patterns: A comprehensive study,? Image and Vision Computing, vol. 27, no. 6, pp. 803? 816, 2009.
[8] C. Padgett and G. W. Cottrell, ?Representing face images for emotion classic? cation,? Advances in neural information processing systems, pp. 894? 900, 1997.
[9] G. Donato, M. S. Bartlett, J. C. Hager, P. Ekman, and T. J. Sejnowski,?Classifying facial actions,? IEEE Transactions on pattern analysis and machine intelligence, vol. 21, no. 10, pp. 974? 989, 1999.
[10] A. J. Calder, A. M. Burton, P. Miller, A. W. Young, and S. Akamatsu,?A principal component analysis of facial expressions,? Vision research, vol. 41, no. 9, pp. 1179? 1208, 2001.



































































































































































































































































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.