








Description
Employee Attrition Predicting using AI Objective:
- The main aim of this project is to predict the employee attrition rate using various machine learning techniques.
- Machine Learning algorithms like SVM and Naive Bayes algorithms are employed in order to predict the attrition rate.
Employee Attrition using Machine Learning
Abstract:
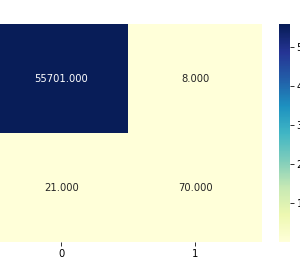
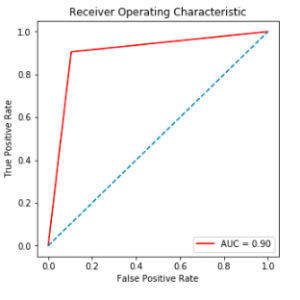
A large number of employees work in a company. There are various factors that affect the number of employees working in a company. One essential aspect we need to consider is that we need to retain potential employees in an organization. The various reasons behind why an employee leaves an organization is being analyzed. Then, the datasets are taken from various sources, various preprocessing techniques are employed in order to remove the null values and then the essential features are extracted in the Feature Extraction Phase. Then, using those features the machine learning model is trained in order to predict the employee attrition rate. Machine learning algorithms like Support Vector and? Naive Baye’s Classifiers are employed in order to predict the employee attrition rate. Finally, the performance of the model is predicted by calculating the accuracy score and showing in the form of a confusion matrix.
Introduction:
A huge volume of data is being generated in various industries. One big task is to collect the data, find patterns hidden in the data and then make predictions.
Various Machine Learning and Data Science concepts are employed in order to analyze the data and then make predictions. Various Machine Learning algorithms like SVM(Support Vector Machine) and Naive Bayes Algorithms are employed in order to make predictions. These are some of the examples of Classification Algorithms. When we want to classify a mail as normal or spam email, then this is an example of a Classification task. When the predicted output is a continuous variable or number, then this is an example of a regression task. Logistic regression is one of the examples of a Regression algorithm. Whenever we want to predict the house prices or stock prices, we need to use various regression algorithms like the Logistic Regression algorithm. Various factors affect the number of employees working in an organization. The datasets are collected from various data sources, then in the preprocessing phase, the null values are removed, and then in the feature extraction phase, the essential features are extracted. Only when we provide good quality data to the machine learning model, then the model will be trained properly and the model will predict properly. After extracting the essential features, it was given to the machine learning model . Various machine learning algorithms like the SVM algorithm are employed in order to predict the employee attrition rate. Then, the results are published. The performance of the model is evaluated by calculating the accuracy score and showing it in the form of a confusion matrix.
Existing System:
In the traditional methods, all the activities inside an organization are carried out manually. The employee records are maintained manually and if any employee wants to leave an organization, they are maintained manually. All this requires a lot of human effort and time and they are prone to a lot of errors. There are many factors involved which may cause a potential employee to leave an organization.?
For example, an employee may leave an organization due to poor salary, lack of proper infrastructure, and many other factors. All these things can’t be predicted manually. To overcome these shortcomings, an employee attrition model is designed by using various machine learning techniques. The model is trained properly by providing the proper data so that the model makes good predictions.
The performance of the model is evaluated by calculating the proper accuracy score.
Disadvantages:
- Prediction accuracy is not good when compared to other methods.
- Less efficient and less robust when compared to other methods.
Proposed System:
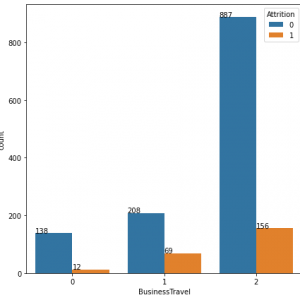
The main aim of this system is to predict the employee attrition rate by employing various machine learning techniques. There are various factors that affect the number of employees in an organization. Parameters like salary, work culture, and work environment affects the employees working in an organization. So, first, we need to collect the datasets from the data source. After collecting the datasets, we need to apply various pre-processing techniques in order to remove null values and unwanted values. Then, various machine learning algorithms like SVM(Support Vector Machine) and Naive Bayes Algorithms are employed in order to determine the employee attrition rate. The results are published. After the results are published, the performance of the model is evaluated by calculating the accuracy score and showing it in the form of a confusion matrix.

Advantages:
- More robust and reliable when compared to all the previous methods.
- Prediction accuracy is good and it consumes less time in order to make predictions.
Block Diagram:

Description:
The block diagram consists of the following modules. Dataset collection, pre-processing module, feature extraction module, SVM Classifier module, prediction module, and the result module. In the dataset module, the datasets are collected from various sources. Then in the pre-processing phase, unwanted null values are removed from the dataset. After cleaning the data, essential features are extracted in order to train the machine learning model. Then, in the classification module, the SVM algorithm is employed in order to predict the employee attrition rate. Then, in the result module, the results are published.
Requirements:
HARDWARE AND SOFTWARE SPECIFICATION
- Hardware:
- 1 GB RAM
- 80 GB Hard Disk
- Intel Processor
- LAN
- Software :
- Windows OS
- Python GUI or Anaconda Navigator
System Requirement:
Operating System: Windows 7 Ultimate 32 bit / Windows XP



























































































































































































































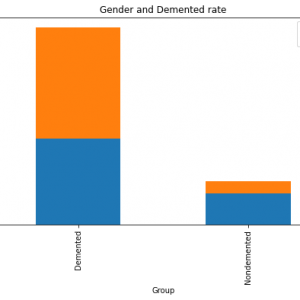
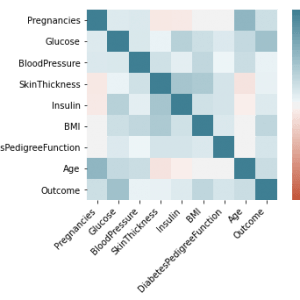







































































































































































































































































































































































































































































































































































































































































Customer Reviews
There are no reviews yet.